続いて、先延ばしにしてきた fopen(), fclose() について説明します。 また、より実用的なファイル入力処理についてもとりあげます。
サンプルで用いたプログラムをもう一度見直して下さい。
#include <stdio.h>
#include <stdlib.h>
int main() {
FILE *inputfile;
int c; // 読み込んだ1バイトを入れておく
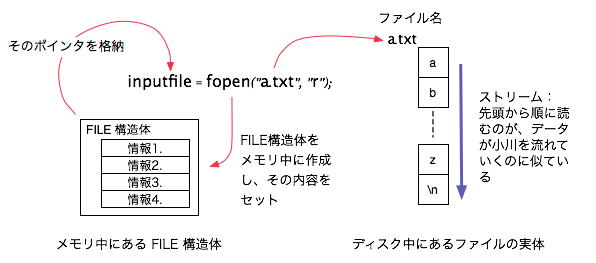
inputfile = fopen("a.txt", "r"); // a.txt ファイルを開く(オープン)
while (1) { // 無限ループ
c = fgetc(inputfile); // ファイルから1バイト読み込んで c に入れる
if (c == EOF) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
printf("#%c#\n", c); // 読んだ文字をそのまま表示
}
fclose(inputfile); // ファイルを閉じる(クローズ)
return 0;
}
(ソースコード fileread1.c)
while ループと、その中にある fgetc() については既に説明しました。 ここでは前処理と後処理にあたる fopen(), fclose() について説明します。
最初に注目すべき箇所は次の行です:
inputfile = fopen("a.txt", "r"); // ファイルを開く(オープン)
ファイルに対して読み書きを行うときは、まず最初にそのファイルを「オープンする」(開く)必要があります。くわしい説明は省略しますが、「ファイルをオープンする」とは、ファイルの読み書きに先立って必要になる色々な準備作業を行うことだと思って下さい。関数 fopen がその処理を行ってくれます。
fopen() には2つの引数があります:
ファイル名を指定するときには、相対パスでも絶対パスでも使用できます。
今回の例では入力とするファイルは a.txt でしたから、第1引数には "a.txt" を指定しています。 fopen の第2引数である "r" はファイルを読む処理のためにオープンすることを表します。("r" はもちろん "read" に由来します。)
fopen 関数は、ファイルのオープンに成功すると、FILE という名前の構造体を1つ作って、それへのポインタを返します。 つまり、「FILE 構造体へのポインタ」が返るわけですが、「FILE 構造体へのポインタ」という言い方は長いので、これ以降、「FILE ポインタ」と呼ぶことにしましょう。 この FILE という構造体はヘッダファイル stdio.h の中で定義されていますが、通常、この構造体の中身がどうなっているかは気にする必要がありません。 ファイル入出力を制御するのに必要なデータが色々と納められているのだと思っておいて下さい。 これ以降、ファイルに対する入出力は、fopen が返してくれたポインタを利用して行うことになります。そこで、このポインタを inputfile という変数に格納しています。
ファイル処理はすべてこの FILE ポインタを通じて行います。 fgetc() がそうだったように、すべてのファイル処理を行う関数は FILE ポインタを指定します。 fopen() 関数の役割は、ファイルというディスク上の実体を、プログラムが直接操作できるメモリ上の変数に結びつけること、と思えば良いでしょう。
なお、このような FILE ポインタをよく「ストリーム (stream)」と呼んでいます。ここで用いているのは入力用のストリームですから「入力ストリーム」と呼ばれます。 「ストリーム」はもともと小川のような細い流れを意味する言葉です。細い流れを1バイトずつデータが流れて来る(あるいは流れて行く)ようなイメージを表現しています。
さて、ファイルを読む処理が終了したとします。 fopen が作ってくれた入力ストリームにももう用はありません。 不要になったストリームには「ファイルのクローズ(ファイルを閉じる)」という処理を行います。
ファイルのクローズを行うには、fclose という関数を呼出します。 引数としては、不要になったストリーム、すなわち FILE ポインタを渡します:
fclose(inputfile); // ファイルを閉じる(クローズ)
fopen() が前処理(準備)だったとすると、fclose() は後処理(後始末)にあたります。
ところで、オープンすべきファイル名を間違えた場合は何が起きるでしょう。
試みに、fopen() に存在しないファイルを指定して、どのようなエラーが発生するか調べて下さい。
fopen() の次に、以下のようにエラー対処のための記述(下4行)を追加して、同様にどのような反応になるか確かめてください。
inputfile = fopen("a.txt", "r"); // ファイルを開く(オープン)
if (inputfile == NULL) { // オープンに失敗した場合
printf("cannot open\n"); // エラーメッセージを出して
exit(1); // 異常終了
}
これは、fopen 関数がファイルのオープンに失敗した場合を考えた処理です。 fopen の第1引数に指定したファイルが実際には存在しなかった場合、(あるいは読み出し許可が与えられていなかった場合)、fopen は失敗します。 fopen は処理に成功した場合は FILE ポインタを返しますが、失敗した場合は NULL ポインタと呼ばれるものを返します。 そこで、上の if 文では、fopen() の結果が NULL ポインタかどうか調べています。 (==の右辺の "NULL" という表記が NULL ポインタを表しています。)
ここで、NULL ポインタについて簡単に説明しておきます。
通常、ポインタというのは、何らかの意味のある対象(変数の置かれているメモリ領域や、配列要素、構造体のメンバなど)を指し示すものなのですが、ときどき、「意味のある対象を決して指さないようなポインタ」「何も指さないポインタ」が欲しくなることがあります。 その一例が今回の fopen() の処理が失敗したときなどで、FILE 構造体は結局用意されなかったので、どこのポインタも返すことができません。 また「どうしようもないので仕方なく NULL ポインタを入れておいた」だけでなく、fopen() はこれを積極的にエラーの通知という意味を与えているわけです。
fgetc() でもファイルの終端を越えてデータを読んだ時に、「文字ではない値」を返すことで、正常な読み取りでなかったことを通知する、というトリックがありました。 FILE ポインタを返すはずの fopen() も同様に、「ポインタとして有り得ない値」を返すことでエラーを通知しているのです。 NULL ポインタは、意味のある対象を決して指さないことが C 言語の規格によって保証されているので、そのような場合にいつも用いられています。NULL は #define によって定義されている定数です。
exit() 関数はエラーなどによってプログラムの実行を中断したいときに利用されます。 引数は整数型で、ここに指定した値がそのままプログラムの終了コードになります。 終了コードは(大学で利用している cc 環境では)シェル変数 $status に格納され、以下に示すような方法で確認できます。
% ./fileread1 cannot open % % echo $status 1 %
より詳しい説明は「コマンドライン引数と終了ステータス」を参照してください。
今度は 1 バイトずつではなく、行ごとに入力処理を行う例を示します。 一般的にファイルを利用する処理では fgetc() による文字ごと( 1 バイト単位)の処理より、行ごと(一行単位)で仕事をすることが多いです。
以下の例は一行ずつデータを読み、行頭に # 記号をつけて出力するだけのものです。
#include <stdio.h>
#include <stdlib.h>
#define LINESIZE 256 // 1行の長さの上限
#define BUFFERSIZE (LINESIZE + 1) // バッファのサイズ
char linebuffer[BUFFERSIZE]; // 1行分の文字列を入れるためのバッファ
int main() {
FILE *inputfile; // 入力ストリームを入れる変数
inputfile = fopen("a.txt", "r"); // ファイルを読み出し用にオープン(開く)
if (inputfile == NULL) { // オープンに失敗した場合
printf("cannot open\n"); // エラーメッセージを出して
exit(1); // 異常終了
}
while (1) { // 無限ループ
char *s; // fgets の返した値を入れる変数
s = fgets(linebuffer, BUFFERSIZE, inputfile); // ファイルから1行読む
if (s == NULL) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
printf("#%s", linebuffer);
}
fclose(inputfile); // ファイルをクローズ(閉じる)
return 0;
}
(ソースコード fgets1.c)
このプログラムをコンパイル・実行すると以下のようになります:
% ./fgets1 #abc #12345 #xyz %
以下、このプログラムについて説明します。
ファイルから 1 行ずつデータを読み出すには fgets() 関数を利用します。
fgets は次のようなプロトタイプを持つ関数です:
char *fgets(char *s, int size, FILE *stream);
fgets の第1引数としては、読み出した1行分の文字列を格納するためのバッファを指定します。 バッファとは、データの受け皿とでも言うべきもので、データを一時的に受け取るためのメモリ領域です。 正確に言うと、fgets に渡すのは、文字列を格納するバッファの先頭へのポインタです。 従って、第1引数 s はchar型を指すポインタとなります。
fgets の第3引数には、入力ストリームを指定します。fgets は、呼び出されるたびに入力ストリームから次の1行を読み出し、文字列としてさきほどのバッファに格納します。例えば、
abc
という1行を読み出したとき、バッファの内容は次の図のようになります:
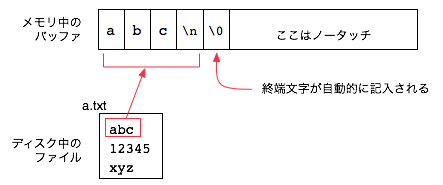
注目すべきなのは、次の2点です:
末尾の '\0' のために1バイトのスペースが必要なので、バッファに格納できる文字列の長さは最大でも「バッファのサイズ - 1」となります。
fgets の第2引数 size には、整数を指定します。すると、fgets は、末尾の '\0' も含めて size バイトまでしかバッファに書き込みません。 通常、size にはバッファのサイズを指定します。 これにより、もし長すぎる行があった場合でも、バッファの終端を越えて書き込みをしてしまうトラブルを防げます。
例題では、次のような形で fgets を使っています。 まず、バッファを確保します:
#define LINESIZE 256 // 1行の長さの上限 #define BUFFERSIZE (LINESIZE + 1) // バッファのサイズ char linebuffer[BUFFERSIZE]; // 1行分の文字列を入れるためのバッファ
例題では 1 行の長さを最大 256 バイトまでと仮定し、冒頭で LINESIZE を 256 と定義しています。 バッファには末尾の '\0' も格納されるので、バッファのサイズ BUFFERSIZE は (LINESIZE + 1) と定義しておきます。 この余分の1バイトを忘れないようにすることが非常に大切です。 今回はバッファを大域の文字配列にとり、そのサイズに BUFFERSIZE を指定しています。
fgets の呼出しは次のような形で行っています:
s = fgets(linebuffer, BUFFERSIZE, inputfile); // ファイルから1行読む
if (s == NULL) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
fgets の第1引数としては文字配列 linebuffer の配列名を与えています。 「ポインタが書かれることが期待される場所に配列名を書くと、それは配列の先頭へのポインタとして扱われる」という規約が C 言語にはありましたから、 これでバッファの先頭へのポインタを与えたことになります。第2引数にはバッファのサイズ BUFFERSIZE、第3引数には入力ストリーム inputfile を与えています。
fgets の返す値は char 型へのポインタです。ファイルから1行を読み出すことに成功した場合、fgets は第1引数をそのまま返します。fgets をくり返し呼び出すと、いつかはファイルの終端に到達するはずです。そうなったときは、ファイルから何も読み出せないので、fgets は NULL ポインタを返すことになります。
これを利用してファイルの終端を検出します。 まず fgets の返した値を変数 s に入れ、直後に s が NULL かどうかを確認するのです。
例題を改造して、下記のように各行ごとの長さ(文字数、バイト長)を合わせて表示するようプログラムを修正してください。
% ./fgets2 4 #abc 6 #12345 4 #xyz %
出力書式は、長さ、区切りの目印として '#' をひとつ、その後に読んだデータファイルの一行の内容、です。
より見栄えの良い出力を得るために、各行の末尾に着いてくる改行を取り除いて、'#' で囲んで各行を表示するように変更して下さい。 改行を取り除いたぶん、長さを一つ短かめに表示するように。(この方が自然でしょう?)
% ./fgets3 3 #abc# 5 #12345# 3 #xyz# %
具体的には一行目は 'a', 'b', 'c', '\n'(改行) の 4 バイトになりますから、文字配列の 4 番目の要素(改行文字)を '\0' に置き換えることになります。
今度は、ファイルから実数や整数、文字列などのデータを読み取ってみましょう。
例題として、ファイルの中に並んだ実数値をすべて合計して出力するプログラムを考えます。 実数値は double 型の値として扱うことにし、ファイルの中には1行に1つずつ実数値が書かれているものとします。
動作を確かめるために、以下のような形式のデータを用意して下さい。 名前は b.dat で良いでしょう。
% cat b.dat ← データファイルの例 3.0 2.0 4.0 1.0 %
以下にサンプルプログラムを示します。 これを手元で実行して下さい。
#include <stdio.h>
#include <stdlib.h>
#define LINESIZE 256 // 1行の長さの上限
#define BUFFERSIZE (LINESIZE + 1) // バッファのサイズ
char linebuffer[BUFFERSIZE]; // 1行分の文字列を入れるためのバッファ
int main() {
FILE *inputfile; // 入力ストリームを入れる変数
double total=0.0; // 合計値
inputfile = fopen("b.dat", "r"); // ファイルを読み出し用にオープン(開く)
if (inputfile == NULL) { // オープンに失敗した場合
printf("cannot open\n"); // エラーメッセージを出して
exit(1); // 異常終了
}
while (1) { // 無限ループ
double x; // 読み出した実数値を入れる変数
char *s; // fgets の返した値を入れる変数
s = fgets(linebuffer, BUFFERSIZE, inputfile); // ファイルから1行読む
if (s == NULL) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
sscanf(linebuffer, "%lf", &x); // 文字列からdouble型の数値を読み取る
total = total + x; // 読んだ数値を total に加算
}
fclose(inputfile); // ファイルをクローズ(閉じる)
printf("Total = %f\n", total); // 合計を表示
return 0;
}
(ソースコード sscanf1.c)
このプログラムをコンパイル・実行すると以下のようになります:
% ./sscanf1 Total = 10.000000 %
以下にプログラムの内容を説明します。
1 行分の文字列データ(文字型配列に格納されている数字っぽく見えるデータ)から double 型の数値を読み取るには、sscanf 関数を用いています:
sscanf(linebuffer, "%lf", &x); // 文字列からdouble型の数値を読み取る
これで、linebuffer に入っている文字列から double 型の数値が読み取られて変数 x に代入されます。
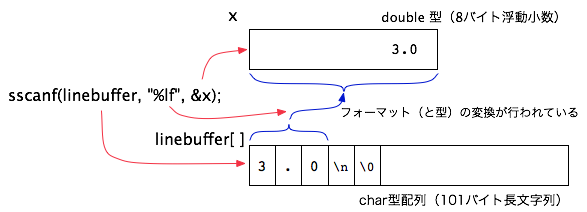
ここでは、sscanf の第2引数として "%lf" というフォーマットを指定していますが、"%d" や "%s" など、他のフォーマットを指定することで、さまざまなフォーマットのデータを読み取ることができます。
また、一行に複数の値が含まれていた場合は下記のようにフォーマット指示と変数のペアを複数並べて処理します。
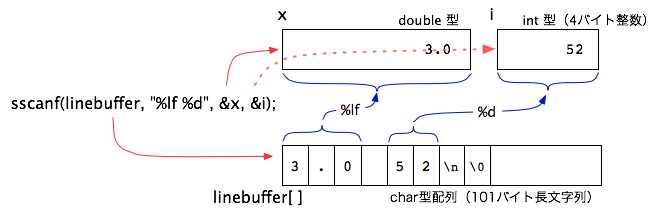
sscanf(linebuffer, "%lf %d", &x, &i); // 文字列から複数の値を読み取る
上の例では double 型の x と int 型の i という二つの変数に同時に値を読み込みます。 左記の例と同様に以下に図示しておきます。 元は文字列だったものが、フォーマット指示に従って変換され、順序よく指定された変数に格納されていることに注意してください。
プログラミング A で scanf 関数を標準(キーボード)入力からデータを読み取るために利用しました。 sscanf 関数は scanf 関数とほとんど同じ動作をします。 異なる点は単に標準入力からデータを得るのではなく、一行文の文字列データを入力とする点だけです。
ここではこれ以上追いませんが、scanf, sscanf は非常に多機能です。 例えば戻り値には実際に幾つのデータを読み取ったかが設定されます。 また複数のデータを読み取るときに、そのデータが空白やタブで区切られているのではなく、カンマで区切られていた (100,200 といった状態) 場合は、フォーマット指定を "%d %d" ではなく "%d,%d" とします。 興味が湧いた時、必要になった時にマニュアル等を参照して調べてみると良いでしょう。
例題では、最後に x を変数 total に足し込むことで、数値の合計を求めています:
total = total + x; // 読んだ数値を total に足し込む
最初の宣言時に total の内容が 0.0 に設定されていることに注意してください。
次のような形式で新車の昨日の売り上げデータが納められたファイルがあるとする:
Vitz T 318 1050000 COROLLA T 315 1302000 ESTIMA T 308 2667000 ...(続く)...
(サンプルデータ cost.txt もしくは漢字版(EUCコード) costj.txt )
各行は以下のように何個かの空白で区切られた4つのフィールドからなっている。
例えば、上の例では Vitz が 318 台、単価が 105 万円となっている。 第3フィールドと第4フィールドの積が、その商品の売り上げとなる。 各行の長さは、行末文字を含めて最大100バイトと仮定する。
このようなファイルが与えられたとき、その内容を1行ずつ読み出しながら、 各商品の売り上げを以下の形式で出力するプログラムを作りなさい。
商品名 売り上げ
コンパイル・実行の例:
% cc -o cost cost.c % ./cost Vitz 333900000 COROLLA 410130000 ESTIMA 821436000 ...(続く)...
ヒント: 各行から 4 つのフィールドのデータを読み出すには、sscanf に与えるフォーマットとして "%s %c %d %d" を用いればよい。
%s というフォーマット指定は、「文字列を読み込んでバッファに格納する」ことを指示します。%s に対応する引数として、sscanf にはバッファの先頭へのポインタを渡さなければなりません。 sscanf は空白文字(タブや行末文字を含む)を見つけると、そこで文字列の読み込みをやめます。 従って、sscanf("abc xyz", "%s", buffer); を実行すると、buffer には "abc" だけが入ります。
上のプログラムに機能追加を行い、最もよく売れた商品とその売り上げを表示する機能を追加してください。 見栄えを良くするために、以下のように商品名は左揃え、売り上げは右揃えにしてください。 (printf() の変換文字列の機能を参照せよ。漢字データを使ってみたが、英字データでも構わない。)
ヴィッツ 333900000 カローラ 410130000 エスティマ 821436000 ...(中略)... シエンタ 121275000 ラッシュ 118104000 -------------------------- エスティマ 821436000