|
| fgets 関数を用いて1行読み出したときのバッファのようす |
この節では、ファイルからデータを読み込んで処理する方法について学びます。
最初の例題として、単にファイルの内容を画面に表示するだけのものを作ります。
プログラムの基本的な考え方は非常に単純で、ファイルから1文字(1バイト)読んではそれを出力することを繰り返そうというものです。
プログラムのわかりやすさのために、このような考え方をとりましたが、 実行速度を考えると1文字ずつ入出力を行うのはかなり非効率です。 何キロバイトかをまとめて読み書きするほうが高速になりますが、 その方法は本節の範囲を越えます。
次のようなプログラムを mycat.c というファイルに記述します:
#include <stdio.h>
#include <stdlib.h>
int main() {
FILE *inputfile; // ファイル構造体へのポインタ
int c; // 読み込んだ1バイトを入れておく
inputfile = fopen("a.txt", "r"); // ファイルを読み出し用にオープン(開く)
while (1) { // 無限ループ
c = fgetc(inputfile); // ファイルから1バイト読み込んで c に入れる
if (c == EOF) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
putchar(c); // c を出力する
}
fclose(inputfile); // ファイルをクローズ(閉じる)
return 0;
}
このプログラムは a.txt というファイルを読み込んでそのまま画面上に出します。 まず a.txt という名前で数行のデータを作成し、プログラムをコンパイル、実行して下さい。
% emacs a.txt % cc -o mycat mycat.c % ./mycat
以下、順を追ってプログラムの内容を説明して行きましょう。
最初に注目すべき箇所は次の行です:
inputfile = fopen(argv[1], "r"); // ファイルを読み出し用にオープン(開く)
ファイルに対して読み書きを行うときは、まず最初にそのファイルを「オープンする」(開く)必要があります。くわしい説明は省略しますが、「ファイルをオープンする」とは、ファイルの読み書きに先立って必要になる色々な準備作業を行うことだと思って下さい。関数 fopen がその処理を行ってくれます。
fopen には2つの引数があります:
ファイル名を指定するときには、相対パスでも絶対パスでも使用できます。
例題では、fopen の第1引数として、コマンドラインの第1引数 argv[1] を指定しています。例えば、コマンドラインから ./mycat file1 が実行された場合、fopen の第1引数として "file1" が与えられることになります。 また、fopen の第2引数に "r" を指定していますが、これはファイルを読み出し専用でオープンすることを表します。("r" はもちろん "read" に由来します。) 読み出し専用にしておけば、プログラムのミスでうっかり書き込みをしてファイルの内容をこわしてしまうのを防ぐことができます。
fopen 関数は、ファイルのオープンに成功すると、FILE という名前の構造体を1つ作って、それへのポインタを返します。 つまり、「FILE 構造体へのポインタ」が返るわけですが、「FILE 構造体へのポインタ」という言い方は長いので、これ以降、「FILE ポインタ」と呼ぶことにしましょう。 この FILE という構造体はヘッダファイル stdio.h の中で定義されていますが、通常、この構造体の中身がどうなっているかは気にする必要がありません。 ファイル入出力を制御するのに必要なデータが色々と納められているのだと思っておいて下さい。 これ以降、ファイルに対する入出力は、fopen が返してくれたポインタを利用して行うことになります。そこで、このポインタを inputfile という変数に格納しています。
なお、このような FILE ポインタをよく「ストリーム (stream)」と呼んでいます。ここで用いているのは入力用のストリームですから「入力ストリーム」と呼ばれます。 「ストリーム」はもともと小川のような細い流れを意味する言葉です。細い流れを1バイトずつデータが流れて来る(あるいは流れて行く)ようなイメージを表現しています。
例題では、このあと次のようなエラー処理を行っています:
if (inputfile == NULL) { // オープンに失敗した場合
exit(1); // 異常終了
}
これは、fopen 関数がファイルのオープンに失敗した場合を考えた処理です。 fopen の第1引数に指定したファイルが実際には存在しなかった場合、あるいは、存在しても読み出し許可が与えられていなかった場合は、ファイルを読み出そうにも読み出しようがないので、fopen の処理は失敗します。そのような場合、fopen は NULL ポインタと呼ばれるものを返します。 そこで、上の if 文では、inputfile の中に保存しておいた FILE ポインタ(fopen が返してくれたポインタ)と NULL ポインタを比較しています。 (==の右辺の "NULL" という表記が NULL ポインタを表しています。) 比較の結果、一致していれば fopen が失敗していたことがわかるので、exit(1); で異常終了しています。 (なお、本来このような場合はエラーメッセージを出すべきなのですが、省略しています。)
ここで、NULL ポインタについて簡単に説明しておきます。
通常、ポインタというのは、何らかの意味のある対象(変数の置かれているメモリ領域や、配列要素、構造体のメンバなど)を指し示すものなのですが、ときどき、「意味のある対象を決して指さないようなポインタ」が欲しくなることがあります。 例えば、fopen の処理が失敗したときのように、意味のある対象を指すポインタを返しようがない場合があります。そのようなときは、しかたがないので「何も指さないポインタ」を返すようにするのです。 NULL ポインタは、意味のある対象を決して指さないことが C 言語の規格によって保証されているので、そのような場合にいつも用いられています。
NULL は #define によって定義されている定数です。
次に、プログラムは while 文による無限ループに入ります:
while (1) { // 無限ループ
while 文の条件部に 1 が与えられており、C 言語において 1 は常に真(条件成立)を表すので、無限にループします。 といっても、本当に無限に繰返しをするわけではなく、 あとで説明するように、ファイルの末端まで読み出しをした所で while 文を抜け出すようにしてあります。
ついでながら、1 が真であるのに対して、0 は常に偽を表します。
C 言語では、0 以外の数はすべて真を表します。従って、 while (1)と書く代りに、例えば while (2) と書いても無限ループになるのですが、普通そういう書き方はしないようです。
ループ内では、ファイルから1バイト分のデータを読み出しては、それを出力するようにしています。 ここでの最初のポイントは fgetc 関数を用いたファイルの読み出しです:
c = fgetc(inputfile); // ファイルから1バイト読み込んで c に入れる
fgetc 関数は、ファイルから1バイトだけデータを読み出してそれを返してくれますので、それを変数 c にしまっています。 fgetc の引数としては、FILE ポインタを渡します。 ここではもちろん、さきほど fopen 関数が返してくれた FILE ポインタを渡します。 fgetc は呼び出されるたびに次の1バイトを読み出して返してくれるので、fgetc を繰返し呼び出すことで、ファイルの内容を全部読み出すことができます。 fgetc が読み出すデータは符号なしの1バイトの数値ですが、あとで説明する事情により、int 型の整数として返されます。 従って、fgetc が返す値を格納する変数は必ず int 型にしなければなりません。
次々にデータを読んで行くと、いつかはファイルの内容をすべて読み出してしまい、ファイルの終端に到達するでしょう。 そうすると、fgetc 関数はデータを読み出せなくなります。 そうなったとき、fgetc はどんな値を返すのでしょうか。
実は、ファイルの終端に到達した状態で fgetc が呼び出されると、fgetc は EOF という定数を返します。 EOF はヘッダファイル stdio.h の中で #define によって定義されており、int 型の数値ですが、1バイトの符号なし整数の範囲(0〜255)には入っていません。 従って、fgetc が返した数値が EOF に一致すれば、それはファイルから読み出されたデータ(0〜255のどれか)ではないことがわかり、ファイルの終端に到達していることが判明します。 そこで、例題では次のようにしてファイルの終端を検出し、ループを抜け出しています:
if (c == EOF) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
ここで、break; という文は while ループを抜け出す働きを持ちます。
プログラミング A で学んだように break; を実行するとループを抜け出すことができます。ループの中にまたループがある場合、break; を含んでいる一番内側のループを抜けます。ただし、break; から見て一番内側にあるのがループではなくて switch 文の場合、switch 文を抜けます。
ちなみに、EOF という言葉は End Of File (ファイルの終端)の略としてよく使われる言葉ですので、上の3行を見れば、一目でファイルの終端を検出しようとしていることが読み取れるはずです。
さて、ここまでの説明を読めば、fgetc 関数が unsigned char 型ではなく int 型の数値を返す理由がわかったものと思います。 1バイトの符号なし整数だけであれば、unsigned char 型の数値の範囲におさまるのですが、fgetc は EOF も返すことがあるので、もっと広い範囲の数値が表せる int 型が用いられているのです。
なお、くどいようですが、EOF が返ってきたときはデータが読み出せなかったのであって、 EOF というデータがファイルに入っていたわけではありませんから注意して下さい。
多くのシステムでは、EOF は (-1) と定義されており、これなら確かに1バイト符号なし整数には入らず、符号つきの int 型にはおさまる数値です。 しかし、EOF の定義はシステム依存であって、オペレーティングシステムの違いなどによって 定義が変わる可能性があり、いつも -1 である保証はありません。 ですから、if (c == EOF) というところを if (c == -1) としてはいけません。 しかし、EOF が1バイトの符号なし整数の範囲の外であることだけは保証されています。
読み出した1バイトを今度は出力するのですが、それには putchar 関数を用いるのが簡単です:
putchar(c); // c を出力する
c の値を putchar に渡すことにより、さきほど読み出した1バイトデータを出力しています。 kterm のような端末ソフトウェアからプログラムを起動した場合、この出力は同じ端末ソフトウェアの画面に表示されます。
putchar の引数は int 型と定められています。しかし、出力するのは1バイトだけですから、int 型の引数の値の最下位8ビットだけが実際には出力されます。 変数 c の型は int でしたから、putchar の引数の型が int になっているおかげで c が そのまま putchar に渡せて好都合です。 (もし、putchar の引数の型が char と定められていたら、 putchar(c); をコンパイルする時に警告が出てうっとうしいはずです。) このように、C 言語では、1バイトの入出力を扱う時にもそれよりサイズの大きな int 型を用いることが多いのです。
putchar 関数も値を返します。その型は int です。putchar は、出力が成功した場合には、出力した1バイトの数値を返しますが、失敗した場合には EOF を返します。失敗する原因としては、例えば出力がファイルにリダイレクトされていて、ディスクの容量不足によりファイルへの書き込みが失敗する場合が考えられます。 従って、本来は putchar 関数の返す値を調べて、それが EOF ならエラー処理をすべきです。 入出力処理を真面目に記述して行くと、このように至る所でエラー処理に気を使わねばならず、 少々面倒にも思えてきますが、プロフェッショナルの仕事ならそれを確実にやらねばなりません。 プロの仕事はきびしいのです。
さて、while ループを終了したとします。もう入力を行う必要はありません。 fopen が作ってくれた入力ストリームにももう用はありません。 このように、入出力を終えてしまってストリームが不要になったときは、 「ファイルのクローズ(ファイルを閉じる)」という処理を行います。 入出力を始めるときには fopen による準備が必要でしたが、 準備が必要なことには後始末も必要なのが道理というもので、 それを行うのが「ファイルのクローズ」という処理なのです。
ファイルのクローズを行うには、fclose という関数を呼出します。 引数としては、不要になったストリーム、すなわち FILE ポインタを渡します:
fclose(inputfile); // ファイルをクローズ(閉じる)
ファイルの行数を数えるプログラム countline.c を作れ。このプログラムは、 コマンドライン引数としてファイル名を与えられると、そのファイルの内容を 読んで、ファイルが含んでいる行の数を出力して終了する。
コンパイル・実行の例を以下に示す:
% cc -o countline countline.c % cat file1 ← 4行からなるファイルの例 abc 12345 pqrstu XYZ % ./countline file1 ← 上のファイルの行数を数えさせてみる 4 ← 行数 4 が出力される
ヒント: ファイルが行末文字を何個含むかを数えればよい。 C 言語では行末文字は '\n' で表されるから、ファイルから1文字入力するたびに それが '\n' と一致するかどうかを調べる。 例えば count という名前の int 型の変数を用意しておき、'\n' を見つけるたびに count の値を1増やす。もちろん、count の初期値は 0 にしておく。 最後に count の値を表示して終了する。
細かいことを言えば、ファイルの最後の行が行末文字で終っていない場合、上の方法では 行数が1だけ少なく表示されることになります。 しかし、UNIX では行末文字で終っていない行は不完全と考えることが多いようですから、 このような場合は無視することにしましょう。(wc コマンドもそのように振る舞います。)
今度は、ファイルから実数や整数、文字列などのデータを読み取ってみましょう。
例題として、ファイルの中に並んだ実数値をすべて合計して出力するプログラムを考えます。 実数値は double 型の値として扱うことにし、ファイルの中には1行に1つずつ実数値が書かれているものとします。 1行の長さは行末文字 '\n' も含めて256バイトまでと仮定することにします。 次のようなプログラムを total2.c というファイルに記述します:
#include <stdio.h>
#include <stdlib.h>
#define LINESIZE 256 // 1行の長さの上限
#define BUFFERSIZE (LINESIZE + 1) // バッファのサイズ
char linebuffer[BUFFERSIZE]; // 1行分の文字列を入れるためのバッファ
int main(int argc, char **argv) {
FILE *inputfile; // 入力ストリームを入れる変数
double total = 0.0; // 合計を入れるための変数
if (argc < 2) { // コマンドライン引数が無い場合
exit(1); // 異常終了
}
inputfile = fopen(argv[1], "r"); // ファイルを読み出し用にオープン(開く)
if (inputfile == NULL) { // オープンに失敗した場合
exit(1); // 異常終了
}
while (1) { // 無限ループ
double x; // 読み出した実数値を入れる変数
char *s; // fgets の返した値を入れる変数
s = fgets(linebuffer, BUFFERSIZE, inputfile); // ファイルから1行読み出して linebuffer に入れる
if (s == NULL) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
sscanf(linebuffer, "%lf", &x); // 文字列からdouble型の数値を読み取る
total = total + x; // 読んだ数値を total に足し込む
}
fclose(inputfile); // ファイルをクローズ(閉じる)
printf("Total = %f\n", total); // 合計を印刷
return 0;
}
このプログラムをコンパイル・実行すると以下のようになります:
% cc -o total2 total2.c % cat data ← データファイルの例 3.0 2.0 4.0 1.0 % ./total2 data ← 上記ファイル中の実数値を合計してみる Total = 10.000000
以下、このプログラムのキーポイントを解説して行きます。 コマンドライン引数が無い場合の処理や、ファイルのオープン・クローズについてはすでに学んだ通りなので、説明を省略します。
ファイルの各行から実数値を読み出すには、
という手順を用います。
プログラミング A で利用した scanf 関数を思い出して下さい。 scanf は標準入力から一行のデータ入力を読み取りますが、これとほぼ同じ動作を、ただし一行ぶんの文字列データを対象に行うのが sscanf 関数です。 なお、fscanf 関数はバッファオーバフローを防げないのでこのクラスでは取り上げません。(そのように学生を誘導したくないので。)
fgets は次のようなプロトタイプを持つ関数です:
char *fgets(char *s, int size, FILE *stream);
fgets の第1引数としては、読み出した1行分の文字列を格納するためのバッファを指定します。 バッファとは、データの受け皿とでも言うべきもので、データを一時的に受け取るためのメモリ領域です。 正確に言うと、fgets に渡すのは、文字列を格納するバッファの先頭へのポインタです。 従って、第1引数 s はchar型を指すポインタとなります。
fgets の第3引数には、入力ストリームを指定します。fgets は、呼び出されるたびに入力ストリームから次の1行を読み出し、文字列としてさきほどのバッファに格納します。例えば、
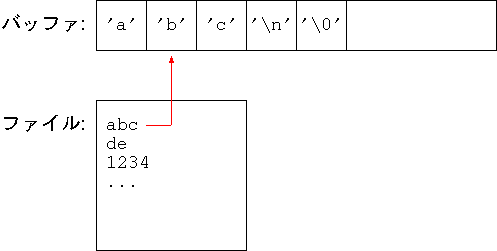
abc
という1行を読み出したとき、バッファの内容は次の図のようになります:
|
|
| fgets 関数を用いて1行読み出したときのバッファのようす |
注目すべきなのは、次の2点です:
末尾の '\0' のために1バイトのスペースが必要なので、バッファに格納できる文字列の長さは最大でも「バッファのサイズ - 1」となります。
fgets の第2引数 size には、整数を指定します。すると、fgets は、末尾の '\0' も含めて size バイトまでしかバッファに書き込みません。 通常、size にはバッファのサイズを指定します。 これにより、もし長すぎる行があった場合でも、バッファの終端を越えて書き込みをしてしまうトラブルを防げます。
fgets の返す値は char 型へのポインタです。ファイルから1行を読み出すことに成功した場合、fgets は第1引数をそのまま返します。読み出せなかった場合は NULL ポインタを返します。fgets をくり返し呼び出すと、いつかはファイルの終端に到達するはずです。そうなったときは、ファイルから何も読み出せないので、fgets は NULL ポインタを返すことになります。これを利用してファイルの終端を検出できます。
例題では、次のような形で fgets を使っています。 まず、バッファを確保します:
#define LINESIZE 256 // 1行の長さの上限 #define BUFFERSIZE (LINESIZE + 1) // バッファのサイズ char linebuffer[BUFFERSIZE]; // 1行分の文字列を入れるためのバッファ
1行の長さを256バイトまでと仮定していたので、最初に LINESIZE を 256 と定義しています。 バッファには末尾の '\0' も格納されるので、バッファのサイズ BUFFERSIZE は (LINESIZE + 1) と定義しておきます。 この余分の1バイトを忘れないようにすることが非常に大切です。 バッファのためのメモリ領域を確保する方法はいくつかありますが、ここでは簡単に大域の文字配列 linebuffer を定義することにして、 そのサイズに BUFFERSIZE を指定しています。
fgets の呼出しは次のような形で行っています:
s = fgets(linebuffer, BUFFERSIZE, inputfile); // ファイルから1行読み出して linebuffer に入れる
if (s == NULL) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
fgets の第1引数としては文字配列 linebuffer の配列名を与えています。 「ポインタが書かれることが期待される場所に配列名を書くと、それは配列の先頭へのポインタとして扱われる」という規約が C 言語にはありましたから、 これでバッファの先頭へのポインタを与えたことになります。第2引数にはバッファのサイズ BUFFERSIZE、第3引数には入力ストリーム inputfile を与えています。
ファイルの終端に達していた場合には、fgets は NULL ポインタを返すはずなので、fgets の返した値を変数 s に入れておき、あとで s の値と NULL を比較して、一致したら while ループを終了しています。
読み出した1行分の文字列から double 型の数値を読み取るには、sscanf 関数を用いています:
sscanf(linebuffer, "%lf", &x); // 文字列からdouble型の数値を読み取る
これで、linebuffer に入っている文字列から double 型の数値が読み取られて変数 x に代入されます。 ここでは、sscanf の第2引数として "%lf" というフォーマットを指定していますが、"%d" や "%s" など、他のフォーマットを指定することで、さまざまなフォーマットのデータを読み取ることができます。
最後に、x を変数 total に足し込むことで、数値の合計を求めます:
total = total + x; // 読んだ数値を total に足し込む
次のような形式でデータが納められたファイルがあるとする:
apple 100 50 orange 20 300 lemon 50 200 ...(続く)...
各行は何個かの空白で区切られた3つのフィールドからなっている。 第1フィールドは文字列で商品名を表し、第2フィールドはその商品の仕入れ個数、 第3フィールドは仕入れ単価を表すものとする。 例えば、上の例では apple の仕入れ個数が100、仕入れ単価が50となっている。 第2フィールドと第3フィールドの積を計算すれば、その商品の仕入れにかかった費用がわかる。
各行の長さは、行末文字を含めて最大100バイトと仮定する。 ファイルが含む行の数に制限はなく、 何行あるかはファイルを実際に読んでみなければわからないとする。 (従って、すべてのデータを読み終ったかどうかは、fgets が返した値を見て ファイルの終端に来たかどうかを調べることにより判定すべきである。)
このようなファイルが与えられたとき、その内容を1行ずつ読み出しながら、 各商品の仕入れにかかった費用を
商品名 仕入れ費用
の形式で出力するプログラムを作りなさい。 プログラムのファイル名は cost.c とする。 すべての数値は int 型として扱うこととし、 入力のファイル名はコマンドライン引数で与えるものとする。
コンパイル・実行の例:
% cc -o cost cost.c % cat data ← 入力ファイルの例 apple 100 50 orange 20 300 lemon 50 200 ...(続く)... % ./cost data apple 5000 orange 6000 lemon 10000 ...(続く)...
ヒント: 各行から3つのフィールドのデータを読み出すには、sscanf に与えるフォーマットとして "%s%d%d" を用いればよい。 各行を読み込むためのバッファ以外に、%s に対応して 商品名を読み込むためのバッファも必要だが、このバッファを十分大きくとらなければ、バッファがあふれる危険性がある。 商品名は1行の文字列の一部分だから、1行の長さと同じサイズのバッファをとれば十分である。(実際にはもう少しだけ小さくてもよいはずだが、わずかな節約に気をつかう必要はない。)
%s というフォーマット指定は、「文字列を読み込んでバッファに格納する」ことを指示します。%s に対応する引数として、sscanf にはバッファの先頭へのポインタを渡さなければなりません。 sscanf は空白文字(タブや行末文字を含む)を見つけると、そこで文字列の読み込みをやめます。 従って、sscanf("abc xyz", "%s", buffer); を実行すると、buffer には "abc" だけが入ります。