
プログラムが使うメモリ領域として、プログラムの機械語が置かれている領域(プログラム領域、またはテキスト領域)のほかに、静的領域とスタック領域があることはすでに学びました。 この章では、もう1つのメモリ領域であるヒープ領域(heap)について学びます。 ヒープを使うと「必要になった時に必要なぶんだけメモリを確保する」ことができます。
例えば、int 型のデータを大量に扱うとして、その個数が 1000 個以内とわかっていたならば、次のように配列として定義すればよいでしょう:
int data[1000];
しかし、データの個数が前もって予測できないような場合は問題です。 上のような配列定義では、配列のサイズは定数でなければならず、 コンパイル時にサイズが決まっていなければなりません。 ところが、ファイルから次々データを読み込むような場合、 ファイルの内容を実際に読み出してみなければ、データの個数がわからないことが多いでしょう。 コンパイル時にサイズを 1000 と決めてしまうと、 データが 1000 個より多いときには対応できません。 それなら、と 1000000 にしてしまうとメモリをムダ使いする場合が多そうです。
このような問題を考えると、
「配列のようなものを確保できるが、 そのサイズや個数をプログラムの実行が始まったあとで決めて良い」
「不要になれば、割り当てられていたメモリを(再利用を目的に)解放することができる」
といったしくみが欲しくなるでしょう。 そのようなしくみは動的メモリ割り当てと呼ばれています。 そして、そのために用意されているメモリ領域をヒープ領域 (または短い呼び方で「ヒープ(heap)」)と呼びます。
このようなしくみの必要性・有用性はいくら強調しても足りないくらいでしょう。 少し現実的な応用をあげてみましょう:
記憶クラスと変数の初期設定で学んだ自動変数の動的領域確保はヒープ領域ではなくスタック領域で行われます。 このあたりはこのクラスではこれ以上追求しません。
ごく簡単な例で、動的なメモリ割り当てを試してみましょう。例題とするのは、 文字列のコピーです。 まず最初に、ヒープを使わないで大域配列へ文字列定数をコピーしてみます。 そのあと、それと比較しながら、ヒープ上の領域にコピーする例を示します。
大域配列へコピーする例は次のようになります:
#include <stdio.h>
#include <stdlib.h>
#include <string.h> // strncpy を使うには string.h をインクルードする。
char *message = "Hello!"; // 文字列定数。長さは6。
#define BUFFERSIZE (6 + 1) // 文字列のコピー先として使う文字配列のサイズ。
char buffer[BUFFERSIZE]; // 文字列のコピー先として使う文字配列。
int main()
{
strncpy(buffer, message, BUFFERSIZE); // 文字列 message を buffer にコピー。
printf("buffer の内容 = %s\n", buffer); // コピーできたかどうか、印刷してみる。
return 0;
}
コンパイル・実行すると、次のようになります:
% cc -o copytoarray copytoarray.c % ./copytoarray buffer の内容 = Hello! %
このプログラムは、"Hello!" という文字列を大域の文字配列 buffer にコピーします。
コピーの処理自体は簡単で、strncpy 関数を呼び出すだけです。 strncpy の使い方について詳しいことはこちらを見てもらうとして、 上の例では strncpy(buffer, message, BUFFERSIZE); を実行することによって、 message というポインタが指す文字列 "Hello!" を buffer にコピーしています。
文字列定数 "Hello!" の長さは6ですが、 文字列の末尾にはヌル文字 '\0' がついているので、 それも合わせると、コピー先の配列 buffer のサイズは、 少なくとも 6 + 1 = 7 は必要です。 ここではちょうど 7 にしています。
最後に、コピーできたことを確認するために、 buffer の内容をprintf関数を用いて標準出力にプリントしています。
次に動的メモリ確保によって同じ処理を行う例を示します。 つまりコピー先は大域配列ではなく、ヒープに領域を確保してそこへコピーします。 大域変数を利用した処理に比べて、作業手順として領域確保と解放の処理が加わります。
ヒープに領域を確保するには、malloc 関数を用います。 あとでその領域が不要になった時は、free関数を用いてメモリを解放します。 malloc と free を使って、ヒープへの文字列のコピーを行うプログラムを書くと次のようになります:
#include <stdio.h>
#include <stdlib.h>
#include <string.h> // strncpy を使うには string.h をインクルードする。
char *message = "Hello!"; // 文字列定数。長さは6。
#define BUFFERSIZE (6 + 1) // 文字列のコピー先として使う領域のサイズ。
int main()
{
char *buffer; // バッファの先頭を指すポインタ
buffer = (char *) malloc(BUFFERSIZE); // ヒープにバッファを確保。
if (buffer == NULL) { // 確保できなかった時は、
fprintf(stderr, "メモリ不足です。\n"); // エラーメッセージを出して異常終了。
exit(1);
}
strncpy(buffer, message, BUFFERSIZE); // 文字列 message を buffer にコピー。
printf("buffer の内容 = %s\n", buffer); // コピーできたかどうか、印刷してみる。
free(buffer); // ヒープ上に確保していたメモリを解放。
return 0;
}
両方のプログラムを比較すると、下図のようになります。
両者の違い、つまり大域変数としての宣言がなくなり、代わりに動的領域確保の前処理と後処理が加わりました。
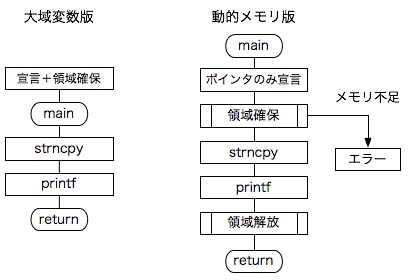
最初に、必要なバイト数(この例では 7 バイト)を
buffer = (char *) malloc(BUFFERSIZE); // ヒープにバッファを確保。
によって確保しています。 ただし、malloc 関数が NULL ポインタを返した場合は malloc に失敗していますからエラーメッセージを出して終了します。
メモリが確保できたら、大域配列を用いたプログラム例と同じように strncpy 関数で "Hello!" を buffer の指す領域にコピーし、printf で buffer の指す領域の内容を表示して確認しています。
ここまで来ると、buffer が指す領域はもう不要ですので、free(buffer); により、領域を解放します。
以下に malloc, free 関数の詳細を説明します。
malloc 関数の名前は、memory allocation (メモリ割り当て)に由来します。
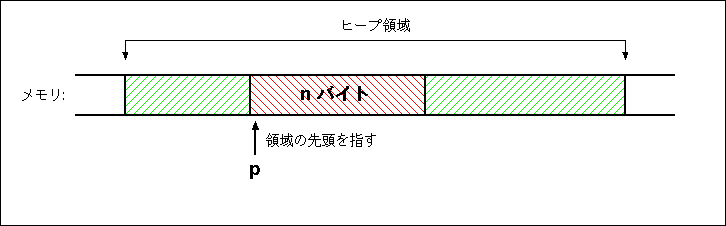
malloc 関数は、引数として符号なしの整数 n を受け取ると、 ヒープから n バイトのサイズのメモリ領域を確保します。 malloc は確保した領域の先頭アドレスをポインタとして返してくれます。 プログラマはこのポインタを利用して、その領域に対する読み出しや書き込みを行えば良い、というアイディアです。 例えば、p を char 型へのポインタとして、
p = malloc(n);
とすると、malloc が返したポインタが p に代入されるので、 p はある領域の先頭を指し、 その領域には n バイト分の char 型のデータが格納できるようになります。
|
| p = malloc(n)の実行結果 |
ただし、メモリが不足している場合には、 n バイトのサイズのメモリが確保できないことがあります。 その場合、malloc は NULL ポインタ を返すので、それをチェックしてエラー対応をしています。 (fopen によるファイルのオープンに失敗した時と同様ですね。)
ところで例題プログラムでは上の代入文は
p = (char *) malloc(n);
のような形に書かれています。この (char *) と書かれた部分は キャスト(型変換)です。 浮動小数点型と整数型の間のキャスト はプログラミング B で学んでいると思いますが、 ここでは、ポインタ型どうしの型変換をしています。 malloc 関数は、void * という型のポインタを返す のですが、代入文の左辺の p は char * 型のポインタ変数なので、 void * 型から char * 型への型変換をして、 型を合わせようとしているのです。
void * 型というのは非常に特殊な型です。 malloc 関数は単にメモリを確保するだけで、それを何に使っても構わない(int 型の領域として使ってもいいし、char 型でも良い)というものです。 つまり malloc が返すポインタは「それが何の(型のための)ポインタであるか特定しない」ものです。 void * 型はそうした用途に使われ、この型のポインタは あらゆるポインタ型に変換できます。
void * 型というのは、ずいぶん変な名前の型に見えると思います。 この名前の意味は何だろう、と悩んでしまう人もいるかも知れません。 以前に void という型が登場した時には、 (1) 関数が値を返さないことを表すために関数の返す値の型を void と宣言する、 (2) 関数が引数を持たないことを表すために、仮引数を void と宣言する、 という2つの使い方を学びました。 その時の void の意味と、void * 型との間にどういう関係があるのだろうか、 と考えこんでしまう人がかなりいるようです。 しかし結論を言うと、 両者の間には何の関係もありませんので、 考えこむ必要はないのです。 void * 型という名前は言ってみれば適当につけられたもので、 別の名前でも良かったのです。
malloc 関数が返してくれたポインタを仮に p とします。 p が指しているメモリ領域が不要になったとき、 free(p); を実行すると、そのメモリ領域を解放することができます。 ただし、次のようなことに注意しなければいけません:
malloc 関数と free 関数について簡単にまとめておきます。
上であげた例題はあまり現実的なものではありません。 malloc を利用する現実的な場面とは、「必要なデータのサイズがプログラム実行後にわかる」タイプのものです。 今までに登場した配列を固定的なサイズ、つまり利用する可能性がある最大量を常に用意する方法では無駄にメモリを要求してしまって効率的でない場合です。
ファイルの中に絵を表すデータが入っているとして、 それを EGGX を用いて画面に表示できるようにしましょう。 簡単のため、 絵は中をぬりつぶした多角形として表現されているとします。 n角形の形は、頂点の座標を n 個並べれば表現できるので、 ファイルの内容は、
頂点の個数 n 1番目の頂点のx座標 1番目の頂点のy座標 2番目の頂点のx座標 2番目の頂点のy座標 ……… n番目の頂点のx座標 n番目の頂点のy座標
という形式をしているものとします。
例えば、左下隅の座標が (100.0, 100.0) で、一辺の長さが 100.0 の正方形は
4 100.0 100.0 200.0 100.0 200.0 200.0 100.0 200.0
のようなファイルで表されます。[このファイル square.txt をダウンロード] これを画面に表示すると、下のようになります。 ただし、縦横のサイズを 0.5倍 に縮小してあります。

|
| 正方形を表示したところ |
正方形は単純すぎて面白くありませんが、もっと芸術的なサンプルが下記の場所に用意してあります。
表示結果の絵は、display コマンドなどで見て下さい。
中が塗りつぶされた多角形を描くには、 EGGX の fillpoly 関数を使います。 fillpoly 関数の解説は、 C プログラミングガイド の9章「EGGX による描画」の中の9.3節「代表的な描画関数」にありますが、 ここでもごく簡単に使い方を示しておきます。fillpoly 関数は
fillpoly(win, x, y, n, i)
の形で使われます。 n は多角形の頂点の数です。 x と y は float 型の配列(の先頭へのポインタ)で、 x[i] と y[i] は、それぞれ、 多角形の i 番目の頂点の x 座標と y 座標です。 配列 x、y はもちろん n 個以上の要素を持たなければいけません。 最後の引数 i は整数で、通常は 0 を指定して下さい。
さて、多角形の頂点の個数はいくらでも大きくできるので、 ファイルの内容を実際に読んでみるまで、データの大きさがわかりません。 従って、頂点の x 座標、 y 座標を格納するために必要な float 型配列の要素数は、 プログラムの実行が始まってからでないと決まらないことになり、 大域配列に頂点座標を読み込むのは不適切ということになります。 そこで、malloc 関数を使ってメモリを確保しようというわけです。
ここで、気をつけなければならないポイントが1つだけあります。 1つ前の例題では、char 型の配列を確保すればよかったので、 配列の要素数と、mallocの引数に指定するバイト数は一致していました。 (具体的には、要素数 = バイト数 = "Hello!" の長さ + 1 = 7 でした。) char 型の大きさは1バイトだからです。 しかし、float 型の大きさは1バイトではなく、普通は4バイトです。 そうすると、必要なメモリのバイト数 = 4 * 要素数、ということになりますから、 malloc の呼び出しは
(float *) malloc(4 * 要素数)
の形になりそうです。 しかし、一応これでプログラムは動くのですが、 この書き方は好ましくなく、sizeof 演算子を用いて、
(float *) malloc(sizeof(float) * 要素数)
のような書き方をするのが良いとされています。 sizeof 演算子を sizeof(型名) の形で用いると、 その型のデータを格納するのに必要なバイト数が求められるので、 float 型の大きさが 4 バイトなら、sizeof(float) は 4 になってくれます。 sizeof 演算子を用いた書き方が好ましい理由はいくつかあります:
もちろん、これは float 型に限った話ではないので、 malloc 関数を用いて動的に配列を確保する場合、たいてい
(型 *) malloc(sizeof(型) * 要素数)
の形になります。
以上のことから、プログラムの概形は下のようになります。 プログラムの一部を ????? のように伏せてあります。
#include <stdio.h>
#include <stdlib.h>
#include <eggx.h>
#define LINEBUFFERSIZE 80 // 一行を読み込むためのバッファのサイズ
char linebuffer[LINEBUFFERSIZE]; // 一行を読み込むためのバッファ
int main()
{
int win;
float xx, yy; // 1つの頂点の x 座標, y 座標を読み込むための変数
int i, n;
float *x, *y; // 動的に確保した配列を指すポインタを保持。
// i 番目の頂点の x 座標、y 座標を x[i]、y[i] に入れることにする。
win=gopen(480, 480);
winname(win, "poly");
fgets(linebuffer, LINEBUFFERSIZE, stdin); // 標準入力を1行読み、
sscanf(linebuffer, "%d", &n); // そこから整数を1個(頂点の数)読みとって n に入れる。
x = ????? // float 型のデータ n 個を入れられる配列を動的に確保
y = ????? // 同上
for (i=0; i<n; i++) { // 頂点の数だけくり返す
fgets(linebuffer, LINEBUFFERSIZE, stdin); // 標準入力を1行読み、
sscanf(linebuffer, "%f %f", &xx, &yy); // そこから float 型のデータを2個読みとって、xx, yy に入れる。
// (i 番目の頂点の x 座標、y 座標)
????? // x 座標を配列の第 i 要素に代入して保持
????? // y 座標を配列の第 i 要素に代入して保持
}
????? // 中を塗りつぶした多角形を描く
????? // x 座標用に確保していたメモリを解放
????? // y 座標用に確保していたメモリを解放
ggetch(win); // キー入力があるまで待つ
return 0;
}
このプログラムは標準入力を読むようになっているので、実行時にデータファイルの内容を読み込ませるには、リダイレクションを利用します。 すなわち、コンパイル・実行は次のような形になります:
% egg -o poly poly.c % ./poly < square.txt
上のプログラムの ????? の部分を正しい表現で埋めて、プログラムを完成させなさい。 プログラムが書けたら、square.txt や locust.txt、horse.txt を読み込ませて動作テストをすること。
問 1. のプログラムでは、多角形を1つしか表示できなかった。もっと複雑な絵も描画できるように、 多角形を複数記述したファイルを読み込んで、それら多角形を全部表示できるようにしよう。
データファイルの形式は次の通りとする。まず最初の行に、多角形の個数 m が書かれている。 その次の行からは、問 1. に対する入力と同じ形式で、 多角形の記述が m 個分並んでいるものとする。
例えば、次のようなファイルは、正方形1個と三角形1個、計2個の多角形を記述している: [このファイル(square-tri.txt)をダウンロード]
2 ← 多角形の個数は 2 4 ← 1個目の多角形である正方形の頂点数 4 100.0 100.0 ← 正方形の1個目の頂点の座標 200.0 100.0 ← 2個目の頂点の座標(以下同様) 200.0 200.0 100.0 200.0 3 ← 2個目の多角形である三角形の頂点数 3 300.0 200.0 ← 三角形の1個目の頂点の座標 400.0 200.0 …… 400.0 300.0 ← 最後の頂点の座標
問 1. の時と同様、データファイルはリダイレクションによって標準入力から読み込むものとする。
実行結果の画面は下図のようになる。ただし、縦横のサイズを 0.5倍 に縮小してある。

|
| square-tri.txt を表示したところ |
このようなプログラムを作りなさい。
なお、芸術的なサンプルデータファイルが下記の場所に用意してある。
プログラムができたら、 これらのデータファイルを読み込ませて動作テストをしてみること。
同じディレクトリに 00list.html として、他の面白いデータも含む一覧があります。 このファイルは Web ブラウザの「開く (Open)」メニューを利用して開くと良いでしょう。
ところで free によるメモリ領域の解放は、その順序を問いません。 つまり malloc を複数回呼び出して幾つもメモリ領域を確保したとします。 それを free で解放する場合に、例えば確保した順に解放しなければならない、といった制約はありません。
メモリの確保と解放をくり返した時のヒープ領域の変化のようすを図示したものを、 別ページに用意しましたので参考にして下さい。