


この節では、ファイルの構造とファイル処理の実態について学びます。 まずファイルを読みながら処理を行うことから試します。
ファイルを扱う処理とはどのようなものでしょう。 例えば以下のようなものが想像できるでしょうか。
ここに挙げた処理はどれも、データをファイルに記憶しておき、それに基づいて処理を行っています。 現代の一般的なコンピュータシステム(クラスで使っている UNIX システムを含む)では、大量のデータを保持するために、よくファイルを利用します。
図中の矢印はデータの流れを意味します。 つまりプログラムは、目的に応じてファイルからデータを読んだり書いたりしているわけですが、これを入力、出力とも表現します。
試みに以下のような内容を持つファイルを Emacs で作って下さい。
abc 12345 xyz
保存した時のファイル名が a.txt だとすると(以後そのように例示します)、以下のように cat コマンドでその内容を確認して下さい。 正しくできていますか。
% cat a.txt abc 12345 xyz %
以下、少しずつこのファイルの内容について説明します。
概念的には今回作成したファイルは以下のようなものだと考えられます。 つまりデータのかたまりがあり、それに a.txt という名前(ラベル)がついている、という解釈です。
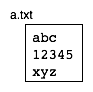
ところでファイルには始まりと終わり(先頭と末尾)があります。 この図の例の場合では、a.txt というファイルは a で始まり z で終わっています。
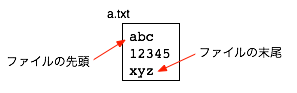
ですがファイルの実体は単なるバイトの列です。 つまり上の図のような構造(二次元構造)ではなく、始まりと終わりの間にデータがまっすぐ並ぶ構造(一次元構造)で表現します。
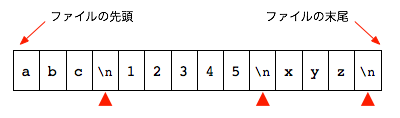
例ではファイルの内容を一バイトずつ四角い枠に入れて図示しています。 abc と 12345 の間にある改行が、改行文字という特殊な一文字になっていることに注意してください。(赤い▲記号で目印をつけておきました。) C 言語では改行文字を '\n' と表現しますので、図でもそのように表記しています。
ファイルの中に見えている文字、abc 12345 xyz だけなら 11 文字つまり 11 バイトの筈ですが、各行の末尾にある改行文字を加えて、このファイルのサイズは合計 14 バイトとなります。
('\n' が「バックスラッシュと n 」に見えるか「円記号と n 」に見えるかはブラウザ等の環境に依存するとおもいますが、両者は C 言語の表記では同じものです。)
試しに先ほど作成したファイルの内容が、実際に図のようになっているかどうか、確認してみましょう。 まず ls コマンドを利用してそのファイルのサイズ(バイト長)を調べます。
% ls -l a.txt -rw-r--r-- 1 yasuda teach 14 May 19 13:18 a.txt %
更新日付の直前がバイト数を意味します。 14 バイトで合っているでしょうか?
次に od コマンドでの例を示します。 これはファイルの内容を一バイトずつ分解して表示します。
% od -c a.txt 0000000 a b c \n 1 2 3 4 5 \n x y z \n 0000016 % % od -t x1 a.txt 0000000 61 62 63 0a 31 32 33 34 35 0a 78 79 7a 0a 0000016 %
一番左の数字 0000000 や 0000016 は先頭から何バイト目からかを意味するラベルで、ファイルの内容とは関係ありません。
od コマンドに -c オプションを指定した場合は、ファイルの内容をできるだけそのまま出そうとします。改行文字などの特殊文字は \n のようにして表示されます。
od コマンドに -t x1 オプションを指定した場合は、ファイルの内容を 1 バイトごとに 16 進数で表記します。
「a」は 61 番文字(16 進数で。10 進数なら 97 番文字)で、続く「b c」は 62, 63 となっています。次は 0a 番文字、すなわち改行となっていることがわかります。
(どの文字が何番かを知るには ASCII文字コード表 などを参考にしてください。)
まず、最も簡単な処理として、ファイルを読んで何かをする処理からはじめましょう。 例えばファイルに図形の座標点が含まれていて、それを読みながら図形を描くというような処理です。
このような処理は、おおよそ以下のような手順で行います。 流れ図と手順を見比べて下さい。
|
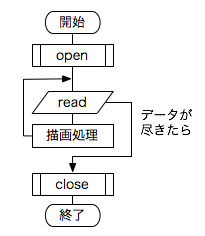
|
ここで理解して欲しいことは、ファイルを利用するためにはオープン・クローズといった前後の処理が必要だ、ということと、ファイルを読む時には前から順に少しずつ読んでいくものなのだ、ということです。
この説明は非常に乱暴なものです。主としてそのようになる、というだけで例外は多くありますし、何より詳細を無視しています。ここでは詳細を追うよりまず全体像をざっと眺めることを優先します。
一般にファイルを利用する処理では、ファイルの内容を前から 1 バイトずつ、または一行ずつ読み出しながら順繰りに作業を進めていくことになります。 例えば以下のような格好です。
以下に実際にファイルを読んで処理を行うプログラムを示します。 図形の描画などは少々処理が複雑ですので、まず最も簡単な「読んだ文字をそのまま画面に表示する」だけのプログラムを例に取ります。 データとして利用するファイルは、上で作った a.txt です。

(ソースコード fileread1.c)
今回初登場の関数が三つです。 fopen(), fclose() はそれぞれファイルのオープン、クローズですが詳細は後で説明します。 まず fgetc() についてだけ注目します。
fgetc() は一回呼び出されるたびに、ファイルからデータを一バイトずつ順に読み出します。
このプログラムでは fgetc() が while ループによって繰り返し実行されます。
つまり 1 バイトずつ読んでは printf() で画面に表示し続け、ファイルを最後まで読み切ったら終了します。
プログラムの構造が上に示した処理の流れ(流れ図)ときれいに一致していることが納得できるでしょうか。
一度ソースコードを取得して実行して下さい。
結果は以下のようになるでしょう。
% ./fileread1 #a# #b# #c# # # #1# #2# #3# #4# #5# # # #x# #y# #z# # # %
ではプログラムの主要な部分の詳細を説明します。 fopen(), fclose() 等はもう少し後回しにします。
このプログラムは 1 バイトずつ読んでは処理を繰り返すというものです。 ループは while によって実現されていますが、そこには(ループがいつ終わるか等を示す)条件が設定されていません。
while (1) {
while 文の条件部には 1 が与えられており、C 言語の条件判定において 1 は常に真(条件成立)を表すので、これは無限にループします。 実際にはファイルの末端まで読み出した所で while 文を抜ける必要があるのですが、その方法については後述します。
ついでながら、1 が真であるのに対して、0 は常に偽を表します。
C 言語では、0 以外の数はすべて真を表します。従って、 while (1)と書く代りに、例えば while (2) と書いても無限ループになるのですが、普通そういう書き方はしないようです。
ループ内では、ファイルから1バイト分のデータを読み出しては、それを出力するようにしています。 ここでの最初のポイントは fgetc 関数を用いたファイルの読み出しです:
c = fgetc(inputfile);
fgetc 関数は、ファイルから1バイトだけデータを読み出してそれを戻り値として返してくれますので、それを変数 c に保存しておきます。 fgetc の引数(inputfile) については後述します。 fgetc は呼び出されるたびに1バイトずつ順に読み出してくれるので、fgetc を繰返し呼び出すことで、ファイルの内容を全部読み出すことができます。
次々にデータを読んで行くと、いつかはファイルの内容をすべて読み出してしまい、ファイルの末尾(終端)に到達するでしょう。 ファイルの終端に到達した状態で fgetc が呼び出されると、fgetc は EOF という定数(一般には -1)を返します。 fgetc が返した数値が EOF に一致すれば、それはファイルから読み出されたデータ(0〜255のどれか)ではないことがわかり、ファイルの終端に到達していることが判明します。 そこで、例題では次のようにしてファイルの終端を検出し、ループを抜け出しています:
if (c == EOF) { // もしファイルの終端に達していたら
break; // while ループから抜け出す
}
ここで、break; という文は while ループを抜け出す働きを持ちます。
プログラミング A で学んだように break; を実行するとループを抜け出すことができます。ループが二重になっている場合、break; を含んでいる一番内側のループを抜けます。ただし、break; から見て一番内側にあるのがループではなくて switch 文の場合、switch 文を抜けます。
EOF が返ってきたときはデータが読み出せなかったのであって、 EOF というデータがファイルに入っていたわけではありません。 EOF はヘッダファイル stdio.h の中で #define によって定義されており、int 型の数値ですが、1バイトのデータとして有り得る範囲(0〜255)には入っていません。 1 バイトのデータを読むはずの fgetc() が、有り得ない値を返すことでファイルの末尾に到達したという異常事態を知らせているのです。
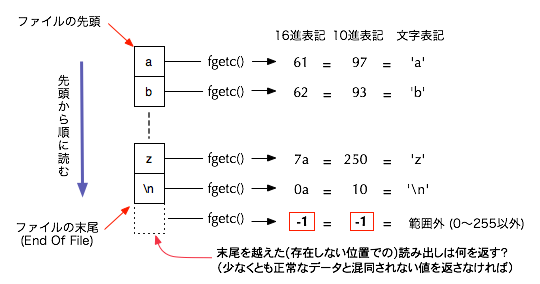
文字として有り得ない範囲の値を返すために、fgetc() 関数の型(つまり戻り値の型)は文字型(char または unsigned char)ではなく int 型です。 プログラム冒頭にある、fgetc() が読み取ったデータを格納するために用意した変数 c が char c; ではなく int c; と宣言されていたことに注目して下さい。
これはある種のトリックです。 しかし C 言語ではこうした手法が良く登場します。 fgetc() の型が文字型ではなく整数型であること、ファイル終端の到達を、それを越えて読もうとしたときに初めて検出すること、また、それを範囲外の値として通知すること、すべてをセットにして正しく処置しなければなりません。
ちなみに、EOF という言葉は End Of File (ファイルの終端)の略としてよく使われる言葉ですので、上の3行を見れば、一目でファイルの終端を検出しようとしていることが読み取れるはずです。 多くのシステムでは、EOF は (-1) と定義されており、これなら確かに1バイト符号なし整数には入らず、符号つきの int 型にはおさまる数値です。 しかし、EOF の定義はシステム依存であって、オペレーティングシステムの違いなどによって 定義が変わる可能性があり、いつも -1 である保証はありません。 ですから、if (c == EOF) というところを if (c == -1) としてはいけません。 しかし、EOF が1バイトの符号なし整数の範囲の外であることだけは保証されています。
サンプルプログラムを元にして、それがファイルの先頭から数えて何バイト目だったかを示す機能を加えて下さい。 実行結果の例を以下に示しておきます。
% ./fileread2 1 #a# 2 #b# 3 #c# 4 # # 5 #1# 6 #2# 7 #3# 8 #4# 9 #5# 10 # # 11 #x# 12 #y# 13 #z# 14 # # %
良く見るとこのプログラムは改行位置で改行文字をそのまま出しているので、改行のところで表示が乱れています。 これを格好良く以下のように出力する機能を加えて下さい。
% ./fileread3 1 #a# 2 #b# 3 #c# 4 ========================= 5 #1# 6 #2# 7 #3# 8 #4# 9 #5# 10 ========================= 11 #x# 12 #y# 13 #z# 14 ========================= %
課題 2. の最後に、合計のバイト数と行数を表示する機能を加えて下さい。
% ./fileread4 1 #a# ..... (中略).... 12 #y# 13 #z# 14 ========================= (total 14 bytes in 3 lines) %
少し挙動を変えて、以下のように行番号をつけて表示するように修正してください。
% ./fileread5 1 : abc 2 : 12345 3 : xyz %
この課題はいくらか複雑かもしれません。 処理の方法も、幾つも思いつきます。 いろいろ考えてみて下さい。 (少々トリッキーであっても)より簡潔なプログラムを歓迎します。
どうしたらいいのかピンと来ない人は、まず流れ図を書きながら、どのような手順で処理を行えばこのような結果を得られるか考えると良いでしょう。 この目的の結果を得られる手順を考えることそのものがプログラミングです。 今までのクラスでは余りそうしたものを求められませんでしたが、実際のところ、プログラミングとはこういうものです。