
|
| プリプロセッサの位置付け |
| プリプロセッサとは | #define命令 | #include命令 | パラメータを持つマクロ | プリプロセッサのその他の機能 |
これまで C のプログラムの中で
#include <stdio.h>
のような命令を何度も使ってきました。これはプリプロセッサ命令と呼ばれるもので、プログラムの他の部分とは異なる特殊な働きをします。プリプロセッサ命令には#include 以外にもいくつかの種類がありますが、それらを使いこなすことは C 言語を活用する上で必須と言えます。しかし、使いこなしにはいささかコツが必要です。この章では、プリプロセッサ命令にはどのようなものがあって、それぞれどのような働きをするのか、それらがどのように便利に使えるかを学びます。
コンパイラについてイメージが湧かない人へ:教科書 page 8 「コンパイルのしくみを知る」参照。
「プリプロセッサ(preprocessor)」という言葉は、直訳するならば「前処理をするもの」、「前処理プログラム」というくらいの意味になります。
C のプログラムをコンパイルするのに、cc というソフトウェアを使ってきましたが、実は cc が行う処理は何段階かに分かれています。我々は自分達の書いた「人間にとって読みやすい表現のプログラム」を「コンピュータが直接実行できる形のプログラム(機械語プログラム)」に変換したいのですが、cc はこの変換をいきなり行うわけではありません。cc は与えられたプログラムをまず最初にプリプロセッサにかけて加工し、その結果に対して本来のコンパイル処理(機械語への変換)を実行するのです。
|
|
| プリプロセッサの位置付け |
一般に、何か重要な処理に先立って、その準備として実行される処理を「前処理(preprocess)」と呼んでいます。プリプロセッサは、本来のコンパイル処理に先立って、その準備となる処理を実行するので、前処理プログラムと呼ばれるわけです。C 言語に関するものであることを明示したいときには「C プリプロセッサ」と呼びます。
プリプロセッサの機能は、コンパイラとは独立に用意されていることもありますし、コンパイラの機能の一部に含まれていることもあります。伝統的に UNIX ではコンパイラ本体とは別に cpp (C PreProcessor の意)と言った名前でプリプロセッサが用意され、cc がそれを呼び出して前処理をするようになっていましたが、現在10号館環境で我々が用いているコンパイラでは、コンパイラ本体にプリプロセッサ機能が含まれています。
cc を起動する際に
% cc -E 何々.c
のように -E オプションを指定すると、本来のコンパイル処理を行なわず、プリプロセッサ機能だけを動作させることができます。プリプロセッサの働きを確めるのに便利です。
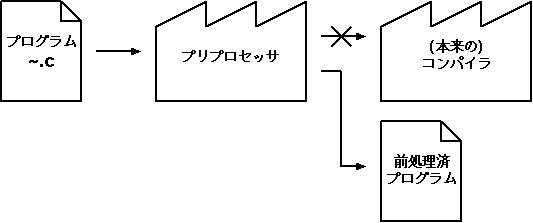
|
cc -Eの働き |
#define命令#define命令の使い方
プリプロセッサ命令のうちで最も多く使われるのが#define命令でしょう。
特に、数値や式に名前をつけるためによく用いられます。
例えば、円周率を用いる計算式をいくつも書かなければならないとき、そのたびに円周率の近似値を3.14159265 のように長々と書くのは面倒ですし、書き間違いをしそうです。 また、こういうややこしい値は覚えるのもいやになることでしょう。 そんなときは、
#define PI 3.14159265
と一行だけ書いておくと、そこから下の行では単に PI と書くだけで済むようになります。 以下にその例を示します。
まずは元の例から。
kei=8.5; shu=2.0 * 3.14159265 * kei; men=3.14159265 * kei * kei; tai= 4.0 / 3.0 * 3.14159265 * kei * kei * kei;
#define を用いた場合
#define PI 3.14159265 ... kei=8.5; shu=2.0 * PI * kei; men=PI * kei * kei; tai= 4.0 / 3.0 * PI * kei * kei * kei;
#define によって、3.14159265 という長い表現に PI という短い名前をつけることができました。ここからあとはプログラム中に PI と書かれているところがあったら、それらはすべて自動的に 3.14159265 に置き換えられ、それからコンパイル処理が行われます。この置き換えはプリプロセッサが行なってくれます。

|
| 置き換え(マクロの展開) |
名前をつける、ということは、言い方をかえれば、その名前に定義を与えたことになります。つまり、上の例では PI というものを 3.14159265 として定義したことになります。このような定義を「マクロ定義」と言い、定義されている語(ここではPI)を「マクロ名」、あるいは短く「マクロ」と言います。また、マクロ名をその定義(ここでは 3.14159265)で置き換えることをマクロの展開と言います。
#define 命令の一般形は
#define マクロ名 定義本体
の形です。
#define とマクロ名の間、及びマクロ名と定義本体の間には空白あるいはタブを1個以上入れる必要があります。また、#define の先頭の `#' 記号は行の先頭に書いて下さい。(`#' の左にスペースを入れても構わないようなプリプロセッサも存在するようですが、あてにしないほうが無難でしょう。)
上の例では定義本体が 3.14159265 という一つの定数でしたが、実は定義本体の部分にはほとんどどんな表現でも書けます。例えば、
#define STRING_MAX_LEN 256 #define BUFFER_SIZE (STRING_MAX_LEN + 1)
のように計算式を書くこともできます。この場合、展開によってまず BUFFER_SIZE が
(STRING_MAX_LEN + 1)に置き換わり、さらにこの中の STRING_MAX_LEN が 256 に置き換わるので、結局 BUFFER_SIZE は (256 + 1)に置き換わることになります。

|
| 展開の連続 |
#define については教科書 page 193 以降にも「マクロを利用する」として説明があります。
上記の半径から円周などを求めるプログラムを実際に作成し、それを -E オプションを付けてコンパイルし、実際に展開された結果がどのようになっているか確認してください。
% cc -E pi.c
cc -E の出力は900行以上にものぼる大変な長さになります。その末尾の部分に注目してください。
長くなる理由については次節の#includeコマンドの解説で説明します。
マクロの展開が正確にはどのように行われるのか、ちょっと確かめてみましょう。 次のようなプログラム(deftest.c)をコンパイルして実行してください。
#include <stdio.h>
#define N 3
int main()
{
int N2 = 5;
printf("N の値は %d\n", N);
printf("N2 の値は %d\n", N2);
return 0;
}
N というマクロ は 3 と定義されていますから、プリプロセッサの働きで N が 3 に置き換わってからコンパイルが行われるはずですが、実際にプログラムを実行してみると以下のような出力が得られます:
N の値は 3 N2 の値は 5
つまり、「N を 3 に置き換える」ように #define を書いたのですが、それより下の全ての N が 3 に展開されるわけではないのです。 上記の printf の結果から推測すると、最初の printf の末尾に書かれた N だけが置換され、それ以外のプログラム中に登場した N の文字は置換されなかったようです。
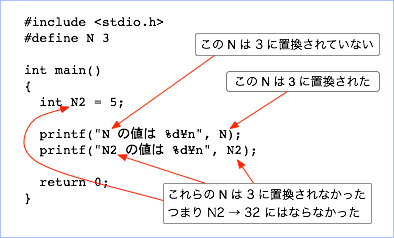
|
| 置き換えられた N と置き換えられなかった N |
3 の値は 3」になったはずですが、実際はそうなっていません。
以上のことは、cc -E を使って確認できます。上のプログラムを cc -E にかけると長い出力が出ますが、その最後の部分は以下のようになります:
…(約900行省略)…
int main()
{
int N2 = 5;
printf("N の値は %d\n", 3);
printf("N2 の値は %d\n", N2);
return 0;
}
N2 がマクロ展開の対象にならない理由について少し詳しく説明しておきます。
プリプロセッサは単語ごとにマクロの展開を行います。N2 は N とは異なる単語なので、展開の対象にならないのです。なお、正確な専門用語としては、「単語」ではなく、「識別子」と言います。識別子は英字から始まる英数字の列です。ただし、_ (下線)も英字に含めるという約束です。簡単に言えば、変数名に使えるような名前が識別子です。
識別子以外のものを置き換えの対象にすることはできません。例えば、10 を 20 に置き換えるようなことはできません。したいとも思わないでしょうが…。
プログラミングA の授業で取り上げられたプログラム egsample.c (単純なループを用いて横棒を画面いっぱいに並べるもの)を修正して、#defineを用いて、画面サイズを決めている数値定数 (400, 400) に名前(マクロ名)をつけなさい。
そこで設定した #define 行の記述を変更するだけで、自由に画面サイズを変更できるように(画面サイズを変更しても横棒が画面いっぱいに並ぶように)なること。
プログラムができたら、コンパイルして正しく動くことを確かめておくこと。
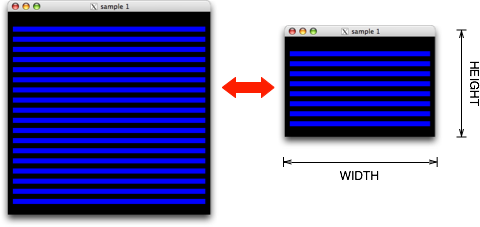
|
| #define の記述を変更するだけで画面サイズが可変となるように |
数値定数に名前を付けることで、プログラムがよりわかりやすく、修正をより容易にできる場合があります。 今回の課題においては、#define を使う以前は画面サイズを変更するためにはどこを修正して良いのかひと目ではわからなかったでしょう。 幅と高さに関係する処理が複数箇所に散在しており、画面サイズの変更はそれらのつじつまを合わせて修正する必要があります。 特にオリジナルのプログラムは縦と横がたまたま同じ 400 というサイズだったため、散在する 400 (またはそれに近い数字)のどちらが縦に関係するもので、どちらが横に関係するのか注意しないとわかりません。
これをプログラムの冒頭に #define を用いて明記し、マクロ名にそれが何を意味する定数なのかわかりやすい名前をつけることによって、その後の修正に対して非常に柔軟になったことがわかるとおもいます。
一般に、プログラムの開発にかかる総コストのうち、プログラムの保守にかかるコストの割合は大変高いと言われています。保守を楽にするために修正の容易なプログラムを書くように心がけるべきです。
#defineの落とし穴すでに述べたように、プリプロセッサの仕事は本来のコンパイル処理とは別のものです。そのため、プリプロセッサ命令の構文と、コンパイル対象になるCの構文とは全く異なっています。このことがしばしば落とし穴になります。
まず、プリプロセッサ命令の中では自由に改行できません。C の構文では、大ざっぱに言って、スペースを書ける所なら自由に改行できます(文字列リテラル内を除く)が、プリプロセッサ命令においては、原則として改行によって命令が切れてしまいます。例えば、
#define BUFFER_SIZE (WINDOW_WIDTH * WINDOW_HEIGHT + OFFSET + 1)
のような長いマクロ定義があったとして、この途中に改行を入れて
#define BUFFER_SIZE (WINDOW_WIDTH * WINDOW_HEIGHT
+ OFFSET + 1) // 悪い例
とすることはできません。改行のところで#define命令が切れてしまい、
そこからあとの `+ OFFSET + 1)' の部分はプリプロセッサ命令によって処理されず、そのままコンパイラに渡されてしまいます。定義が長すぎて読みづらいといった理由で改行を入れたい場合は、改行の直前に`\' (バックスラッシュ)を入れることで、次の行に命令の続きを書くことができます。
#define BUFFER_SIZE (WINDOW_WIDTH * WINDOW_HEIGHT \
+ OFFSET + 1)
もう一つの問題は、プリプロセッサがどんな奇妙なマクロでも全く機械的に展開してしまうことです。展開の結果C言語の文法に合わないプログラムができてもプリプロセッサはまるでお構いなしで、エラーメッセージ1つ出しません。エラーはその後のコンパイル処理に進んでから検出されるので、エラーの原因がわかりにくくなることがあります。 例えば、
#define NONSENSE %*!? // ばかげた例
int i = NONSENSE;
のようなプログラムを与えてもプリプロセッサは何のエラーも出さず、黙って NONSENSEを %*!? に置き換えてくれます。もちろん、展開の結果できる `int i = %*!?;' という文は文法的にデタラメです。
まあ、ここまでデタラメなマクロは皆さんまず作らないでしょう。 しかし、次のプログラムはいかにもやりそうなミスの例です:
#define NDATA 100; // ここのセミコロンがまずい int main() { int i; for (i=0; i < NDATA; i++) { /* 中略 */ } }
このプログラムの問題は、#define命令の末尾に`;' (セミコロン) がついていることです。C 言語では行の末尾にセミコロンが来ることが多いので、うっかりこんな所にもセミコロンをつけてしまう、というミスをしがちです。このミスにより、NDATAが100に展開されるようにしたつもりが実際には 100; に展開されてしまいます。マクロ展開が済んだあと、このプログラムの for 文は
for (i=0; i < 100;; i++) { // ここに構文エラー /* 中略 */ }
の形になり、セミコロンが3個あるためにコンパイル時エラーとなります。しかし、困ったことに、
for文に対して出るが、本当の問題はそこから離れた#define命令にあるので問題を見つけにくい。
ということになります。
#include命令#include命令の働き
#include命令は
#include <ファイル名>
または
#include "ファイル名"
という形で使われます。プリプロセッサは、こういった行を見つけると、ファイル名で示されたファイルの中身をその部分に挿入します。ファイルの中身をそこに「含める(include)」ということから #include 命令という名前がついたわけです。 例えば、
#include <stdio.h>
と書いてあったら、その行は stdio.h というファイルの中身で置き換えられます。stdio.hの中身がごっそりそこに読み込まれるのです。#include 命令によって読み込まれるファイルは一般にヘッダファイルと呼ばれます。ヘッダファイルの拡張子は .h です。
ヘッダファイルはインクルードファイルと呼ばれることもあります。
ヘッダファイルが読み込まれることで、プログラムの行数は当然増えます。もしもヘッダファイルの中にまた #include 命令があると、そこでまた別のヘッダファイルの読み込みが起きます。実際、10号館の Linux 環境では、stdio.h の中でまた features.h、stddef.h など多くのヘッダファイルを読み込むようになっています。前節で cc -E の働きを試した際にファイルが900行以上にも膨れ上がってしまったのは、こうして多くのヘッダファイルが読み込まれたためです。

|
| #include によるファイルの挿入 |
ところで、stdio.h というファイルは一体どこにあるのでしょうか? つまり、#include 命令によって指定されたヘッダファイルをプリプロセッサはどこから探し出してくるのでしょうか。これについては、次のような規則があります。
システム標準の場所がどこであるかは、その時使っているプログラミング環境によって違います。
Linux を始め、大抵の UNIX では /usr/include というディレクトリの下に標準的なヘッダファイルが置かれています。例えば stdio.h の正体は /usr/include/stdio.hです。
ヘッダファイルはたくさんあるので、整理のため /usr/include の下にサブディレクトリをいくつか作って、そこにヘッダファイルを置いていることもあります。例えば、/usr/include/sys というディレクトリに types.h というファイルがありますが、これをを読み込みたければ
#include <sys/types.h> と書きます。
#include については教科書 page 22 以降にも説明があります。
ところで、ヘッダファイルの中には何が書かれているのでしょうか。そしてそれらがどう役に立つのでしょうか。
ヘッダファイルの中に書かれる事柄のうち主なものを3つだけあげてみます:
これら1〜3には共通点があります。それは、どれも一種の定義・宣言であって、「複数のファイルで共通に使いたくなるような情報」ばかりである、ということです。
1 の「マクロの定義」については、そのことは明らかでしょう。便利なマクロを作ったら、それを多くのプログラムで使いたくなるはずです。例えば、以前に示した円周率 PI のマクロが便利だと思ったら、きっとあちこちで使うようになるでしょう。 しかし、PI を使いたくなるたびに全部のファイルに PI のマクロ定義を書くのはいかにも無駄ですね。こういうものは一度だけヘッダファイルに書いておいて、それを各プログラムに #include で取り込めば良いのです。こうすればマクロの定義を修正するときに一カ所だけ修正すれば済みます。 ヘッダファイルというのは、一度だけ作成しておいて、それを複数のプログラムから #include する、という使い方で威力を発揮するものなのです。
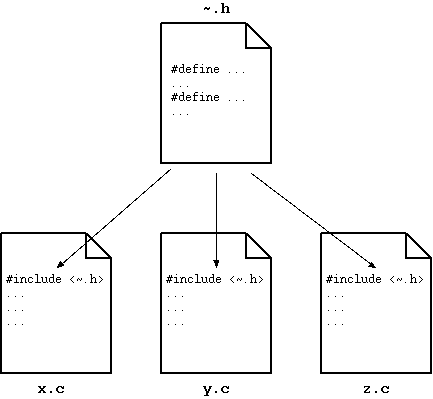
|
実は、円周率のマクロ定義は自分で作らなくても最初から math.h というファイルに用意されています。ただし、マクロ名は PI ではなく、M_PIです。定義も 3.14159 ではなく、もっと精度の良い 3.14159265358979323846 になっています。円周率の近似値が必要になったら、#include <math.h>と書くだけで良いのです。
2, 3 の「新しい型の定義」「便利な関数の宣言」についても同じことが言えます。便利なもの一度用意したら、多くのプログラムで使いたいはずですから、これもヘッダファイルに入れておけばよいのです。
プリプロセッサはヘッダファイルの中身を全く機械的に挿入しますから、原理的にはどんな内容でもヘッダファイルに書くことができます。しかし現実問題として、以下のような内容はヘッダファイルに書くべきでありません。
こういうものを書いてしまうと、そのヘッダファイルを複数のファイルから #include した時に問題が発生します。
1. に該当する例としては、`int i = 0;' のような変数定義や `double a[3] = {10, 20, 30};' のような配列定義があります。
前者では、変数 i に対応して、int型の整数を入れるのに必要な記憶領域が確保され、初期値として 0 が設定されます。後者では、配列 a に必要な記憶領域が確保されて、{10, 20, 30} で初期化されます。今、仮にヘッダファイルに `int i = 0;' と記述したとして、それを x.c と y.c の両方で #include したとします。すると、`cc x.c y.c' のようにコンパイルした時、「i が多重に定義されている」という意味のエラーメッセージが出て失敗します。その理由は、x.c と y.c の両方に `int i = 0;' が含まれてしまったために、「同じ i という変数名で2か所の記憶領域を確保しようとしている」と判断されてしまうからです。ヘッダファイルに `double a[3] = {10, 20, 30};' を記述した場合も同様の理由でコンパイルに失敗します。
2. で失敗する理由も同じようなものです。ヘッダファイルの中で次のように関数 f を定義したとします:
int f(int n)
{
/* ここに何か関数定義が書かれている */
}
そのようなヘッダファイルを x.c と y.c の両方で #include してしまうと、`cc x.c y.c' のようにコンパイルした時、「f が多重に定義されている」という意味のエラーメッセージが出て失敗します。x.c と y.c の両方に `f' の定義が含まれてしまったので、fの定義が2つあると判断されたのです。
今の段階ではそもそもこの `cc x.c y.c' のようにコンパイルする状況が想像できないと思います。
興味のある人は「分割コンパイルとリンケージ」の資料を見てください。
上で説明した以外にもプリプロセッサは様々な機能を持っています。 詳しい説明はしませんが、以下にリストアップしておきますので、興味と必要に応じて参考書などで調べてみて下さい。
#define 再び
#define命令を用いることで、定数や式などに名前をつけられることはすでに説明しましたが、実は #define命令はもっと強力な機能を持っています。それがパラメータつきのマクロ定義です。
#define SQ(x) ((x) * (x))
上の #define 命令において、SQがマクロ名、x がパラメータ、((x) * (x))が定義本体です。この形のマクロ定義が便利なのは、パラメータ x の部分を色々な表現で置き換えられることです。
例えば、SQがSQ(3)の形で使われていたら、プリプロセッサはそれを ((3) * (3)) に展開します。つまり、定義本体の中のパラメータ x が 3 に置き換わった形に展開されるのです。これから察しのつくとおり、SQ は2乗を計算するためのマクロです。(SQ の名は square に由来します。)
とは言っても、SQ(3)が ((3) * (3)) に展開されても大してうれしくないと思われるかも知れません。しかし、SQ(a[i+j+1]) くらいになるとどうでしょうか。展開後の ((a[i+j+1]) * (a[i+j+1])) に比べてかなり見やすいのではないでしょうか。
パラメータは複数持たせることもできるので、マクロ定義の一般形は次のようになります。
#define マクロ名(パラメータ1, ..., パラメータn) 定義本体
関数の仮引数と同じように、マクロのパラメータを並べる時もコンマで区切ることに注意して下さい。また、マクロ名とその直後の開き丸カッコ `(' の間にスペースを入れてはいけません。
#define マクロ名 (パラメータ1, ..., パラメータn) 定義本体 // これはダメ!
こう書いてしまうと、パラメータのないマクロだと思われてしまいます。
パラメータを複数持つマクロとして、次のような例が考えられます。
#define dist2(x,y) (SQ(x[0]-y[0]) + SQ(x[1]-y[1]) + SQ(x[2]-y[2]))
x が第1パラメータ、yが第2パラメータです。定義本体の中で、前に定義した2乗を求めるマクロ SQ を利用しています。dist2(x,y) は、3次元空間内の2点
(x[0], x[1], x[2]) と (y[0], y[1], y[2]) との間の距離(distance) の2乗を求めるマクロになっています。
(数学で習った公式
|
|
を思い出して下さい。)
#defineの落とし穴(その2)
SQの定義本体が ((x) * (x)) になっているのを見て、
「むやみとカッコが多いなあ」と思った人がいるかも知れません。しかし、このカッコにはちゃんと意味があります。カッコを省いて
#define SQ(x) x * x // これはダメ!
とすると、トラブルが発生します。(a + 1) の2乗を計算するつもりで
SQ(a + 1)と書くと a + 1 * a + 1 に展開されてしまいます。加算より乗算が優先するので、これは a + (1 * a) + 1 と同じ、すなわち、a + a + 1 と同じになってしまいます。一方、((x) * (x)) のほうを採用しておけば、ちゃんと ((a + 1) * (a + 1)) に展開されるので、演算子の優先順位で問題が生じる危険がありません。つまり、マクロの定義本体の中では、パラメータはカッコでくくっておくのが無難です。
「パラメータをカッコでくくる理由はわかった。でも、((x) * (x))はやり過ぎじゃない? (x) * (x)で十分じゃないのかな?」と思われるかも知れません。しかし、定義本体に演算が含まれている場合は、定義本体の全体もカッコでくくったほうが無難です。なぜなのか、今度は dist2 の例で考えてみましょう。dist2 の定義本体の一番外側のカッコを省いて
#define dist2(x,y) SQ(x[0]-y[0]) + SQ(x[1]-y[1]) + SQ(x[2]-y[2]) // 悪い例
と書いたとします。このとき、2点を結ぶ線分を半径とする円の面積を求めようとして
M_PI * dist2(x,y) と書くと、M_PI をかける乗算が加算より優先するために (M_PI * SQ(x[0]-y[0])) + SQ(x[1]-y[1]) + SQ(x[2]-y[2]) に相当する計算がされてしまい、期待した結果になりません。従って、定義本体の全体もカッコでくくっておいたほうが無難です。余分にカッコでくくってあっても害にはならないので、心配な時はくくっておけばよいでしょう。
パラメータ無しのマクロの場合も、定義本体が式になっている場合は一般的に本体全体をカッコでくくったほうが無難です。しかし、#define NINZUU 60 のような例で、60をカッコでくくる必要はありません。定数しか出て来ないので、演算の優先順位の問題が発生しないからです。ただし、定数でも負の定数の場合は要注意です。#define N (-100) のような例では、カッコを省略しないほうが良いでしょう。符号を表すマイナス記号も演算記号になるからです。めったに問題にはならないはずですが、具体的にどんなケースで失敗するのか、興味のある人は考えてみると面白いかも知れません。
パラメータを持つマクロ odd(x) を定義し、引数 x が奇数なら真、偶数なら偽となるようにしなさい。定義は odd.h というファイルに書きなさい。(ヒント: x を 2で割った余りが1なら奇数。)
プログラムを書いたら、下のプログラムをコンパイル・実行して正しく動くことを確かめなさい。
#include <stdio.h>
#include "odd.h"
int main()
{
int i;
for (i = 0; i < 5; i++) {
if (odd(i)) {
printf("%d は奇数です。\n", i);
} else {
printf("%d は奇数ではありません。\n", i);
}
}
}
コンパイル・実行すると次のようになるはずです。
apc3k003(238)% cc -o odd odd.c apc3k003(239)% ./odd 0 は奇数ではありません。 1 は奇数です。 2 は奇数ではありません。 3 は奇数です。 4 は奇数ではありません。
#defineの落とし穴(その3)
マクロの引数部分にはあまり複雑な式を書かないほうが無難です。
せいぜい、四則演算や配列要素の値の取り出し、それらを組み合せた式くらいにとどめるべきです。
関数呼出しや i++ とか i-- といった形の式(つまり変数や配列の中身を変更するような式)をマクロの引数部分に書くとトラブルになりやすいので、やめておきましょう。
以下、トラブルが起きる理由を一応説明しますが、非常に細かい話になりますし、難しいので初めて読む時は飛ばしても良いですし、すぐに理解できなくても構いません。
再び SQ(x) の例を考えましょう。
SQ(x)の定義本体である ((x) * (x)) にはパラメータ x が2回出てきます。従って、SQ の引数として与えられた式は2か所に複製されてしまい、その結果2回計算される可能性があります。これがトラブルの種になります。
今、関数 f() の計算には非常に長い時間がかかるとします。例えば1時間かかるとしましょう。f()の計算結果の2乗がほしいと思った時、y=SQ(f()) と書いたらどうなるでしょうか。SQ(f())はマクロ展開によって ((f()) * (f())) になるので、f() の呼出しが2回実行されてしまい、計算に1時間×2 = 2時間以上かかります。これはひどいので、
z = f(); // f() を一回だけ計算して結果を zにとっておく
y = SQ(z);
というようなプログラムに変形すべきです。
「面倒くさいからそういう変形はコンパイラが勝手にやってくれないかな」と思うかも知れません。実を言うと、まともな C コンパイラなら、引数が簡単な式の場合は勝手にそういう変形をしてコンパイルしてくれます。例えば、SQ(a[n]+1)といった形なら、
z = a[n]+1; // a[n]+1 を一回だけ計算して結果を zにとっておく
y = SQ(z);
に相当する計算をしてくれます。
引数の計算を1回にまとめたことにより計算の手間が少し減ります。
しかし、関数呼出しの場合には、一般に言って2回の計算を1回にまとめると結果が変わってしまいますから、コンパイラは1回にまとめようとしません。
例えば、f()を呼び出すとチャイムが1回鳴るとします。
2回呼び出すとチャイムが2回鳴りますが、1回にまとめるとチャイムも1回になってしまいます。
また、乱数を使っている関数は、1回目と2回目で計算結果が違ってくるので、やはり1回にまとめられません。
逆に、a[n]+1に限らず、2回の計算が同じになることが明らかな式ならコンパイラは1回にまとめてしまいます。四則演算とか、配列要素の値の取り出しなら大丈夫です。
一方、関数呼出しの場合は、どんな複雑な処理をしているか知れたものではないので、1回にまとめられるかどうかコンパイラが自動的に判断するのは不可能です。
i++のような式の計算も2回を1回にまとめられません。1回計算すると i の値が1増えますが、2回なら 2 増えるからです。
ちょっと難しかったですね。とりあえず、「マクロの引数は簡単な式だけにしておこう」ということだけは覚えておいて下さい。そもそもややこしい式は理解しにくいですからね。
引数を持つマクロと関数とはよく似ています。 少なくとも呼び出しかたはそっくりです。 UNIX には、まるで関数のように使えるマクロが多数用意されていて、普通に使っている分にはそれらがマクロであることを意識しないでも構わないことが多いのです。 また、プログラムを書いている時、ある処理を記述するのにそれを関数として定義することもできるし、マクロとして定義することもできて、どちらにするか迷うようなこともあります。 しかし、関数とマクロの間にははっきりした違いがあり、重要な相違点についてはしっかり押さえておくべきです。 以下では、これらがどう違うのか、どう使い分けるのが良いかを考えて行きましょう。
詳しいことは秋学期のコンピュータ基礎I・IIで学びますが、CPU が関数呼出しを実行するには多少の手間がかかります。この手間を嫌ってマクロを使う、というのがマクロの使用の大きな動機の一つです。
例えば、2乗の計算をするのに、前に定義した SQを使う代りに、次のような関数 square(x)を作っておいて、それを呼出すことも可能です:
double square(double x) // 引数 x の2乗を返す関数
{
return x * x;
}
しかし、これはずいぶん無駄なように感じられます。この関数の中でやっていることは本質的には x * x という乗算 1 つだけです。たったこれだけのことをするために、関数に引数を渡すための処理や、return 文の処理など、関数の開始・終了のための手間をかけるのは割に合わないような気もします。その点、マクロ呼出しの場合は、((x) * (x)) の形に展開されてからコンパイルされるので、式 * 式 の形に書いても SQ(式) の形に書いてもプログラムの実行速度は同じです。プログラムが少々見やすくなった上に実行速度が変わらないなら、マクロを使う価値はあります。一方、関数内部の処理が複雑なら、相対的に見て関数呼出しの手間は問題にならなくなるので、マクロにする意味は薄れます。
残念ながら、マクロの展開という機構ではあまり複雑な処理はできません。 早い話がパラメータを実際の引数で機械的に置き換えるという単純なしかけしか 持っていないのですから、しかたがありません。
条件判断ができないので、「この条件が成り立ったら、こういう形に展開する。成り立たなかったら別の形に展開する。」といった芸当はできません。ループもできません。マクロの定義本体で別のマクロを呼ぶことはできますが、マクロが自分自身を呼ぶことはできません。(あとで学ぶように、関数はその関数自身を呼び出せます。) 関数(正確には関数へのポインタ)は変数に入れたり、別の関数に引数として渡したりすることができますが、マクロではそんなことはできません。
このあたりの事情はプログラミング言語ごとに全く異なります。 最も過激な柔軟性を持つのが Lisp 言語で、マクロの展開時に条件判断だろうがループだろうがありとあらゆる計算ができます。かと思えば、Java 言語は、設計者がプリプロセッサの落とし穴を嫌ったらしく、そもそもプリプロセッサを持っていません。定数に名前をつける方法は別に用意されています。
非常に複雑な長い表現に展開されるようなマクロを定義したとしましょう。 そのマクロを何度も使うと、そのたびに長い表現に展開され、それらが全てコンパイルされるので、プログラムの大きさが膨張してしまいます。 記憶容量がたっぷりあるコンピュータでは多少プログラムが大きくなっても問題になりませんが、ごく小型のコンピュータでは問題になり得ます。 これに対して、関数定義は一度だけしかコンパイルされませんし、関数をたびたび呼び出してもプログラムはそう長くなりません。
高等テクニックに属するのでこの授業では説明しませんが、あるしかけを用いると、関数では書けないような便利なマクロを作れます。例えば、debug_print(x);と書けば "x の値は〜です" (「〜」の部分に現在の値が入る)と印刷され、
debug_print(y);と書けば "y の値は〜です" と印刷されるような
マクロが作れます。しかし、関数でこんなことはできません。
以上のような考察から、割合簡単な処理を高速に実行したい場合にマクロで記述するメリットが生まれやすく、複雑な処理では関数で記述すべきケースが多くなると考えられます。しかし、明確な線引きができるものではないので、マクロの落とし穴にも注意した上で使い分けましょう。