この節では、ファイルへデータを書き込む方法について学びます。
プログラミング A で最初に作ったプログラムを思い出して下さい。 ただ単に標準出力(ターミナル)に表示するだけのものです。
#include <stdio.h>
int main() {
printf("My name is Enokida Yuuichirou.\n");
return 0;
}
これは My name is Enokida Yuuichirou. という表示をただ行うプログラムですが、これの出力を標準出力ではなくファイルに行うようにします。 つまり printf による出力先をファイルにするのです。
プログラムは以下のようになります。 手元に保存して、実行してください。
#include <stdio.h>
#include <stdlib.h>
int main() {
FILE *outputfile; // 出力ストリーム
outputfile = fopen("d.txt", "w"); // ファイルを書き込み用にオープン(開く)
if (outputfile == NULL) { // オープンに失敗した場合
printf("cannot open\n"); // エラーメッセージを出して
exit(1); // 異常終了
}
fprintf(outputfile, "My name is Enokida Yuuichirou.\n"); // ファイルに書く
fclose(outputfile); // ファイルをクローズ(閉じる)
return 0;
}
(ソースコード filewrite2.c)
実行例です。
% cat d.txt cat: d.txt: No such file or directory ←この時点ではファイルが存在しなかった % cc -o filewrite2 filewrite2.c % ./filewrite2 ←実行したことによって % cat d.txt My name is Enokida Yuuichirou. ←ファイルができた %
以下のように比較すると、ファイルに出力するために何が増えて何が変更されたかがわかるでしょう。

FILE ポインタを用意し、fopen() によってオープンし、fclose() によって閉じるまでの間に処理をする、という点では入力処理とまったく同じ構造です。 fopen がエラーを起こした時(有り得ないファイル名を指定してしまった等)のエラー対応の仕組みについても全く同じです。 目新しいのは以下の二点でしょう。
以降にそれらの点について順次説明します。
モード指定(第二引数)を "r" ではなく "w" にすることで、fopen はファイルを書き込み用にオープンします。 (もちろん、"w" は "write" に由来します。)
outputfile = fopen(ファイル名, "w"); // ファイルを書き込み用にオープン
ファイルが無事にオープンできたとき、 fopen はやはり FILE 構造体へのポインタ(ストリーム)を返しますので、それ以降、 そのポインタを通じてファイルへの出力を行います。
書き込みモードが指定されたとき、fopen は、第1引数に与えられたファイル名を持つファイルがまだ存在しなければ、それを作成します。作成直後、ファイルの内容は空です。気をつけなければならないのは、指定されたファイル名のファイルがすでに存在する場合です。 その場合、そのファイルの内容はいったん完全に消され、空になってしまいます。 ファイルの内容が消されては困る場合、 このモードでオープンしないように注意しなければなりません。
ここまでで、"r" と "w" という2つのファイルオープンモードについて学びましたが、他のファイルオープンモードについても少し触れておきましょう。
"w" モードでは、すでに存在するファイルを開くとその内容が空になるのでしたが、 そうではなく、現在の内容はそのままにしておいて、 その末尾に新たな内容を書き足したい場合もよくあるでしょう。 例えば、ソフトウェアの動作記録をファイルに残していくような場合、 以前の記録をそのままにして、新たな記録をファイル末尾に書き足せばいいはずです。 そのようなときは、"a" モード(追加モード、"a" は append に由来)を使用します。
また、すでに存在するファイルの内容を更新するような場合、現在の内容の読み出しと、更新後の内容の書き込みの両方を行わねばならないので、ファイルを読み書き両用にオープンする必要があります。そのような場合は、"r+", "w+", "a+" の3つのモードを用います。ただし、この3つのモードの使い方は少し複雑なので、この章では詳しく解説しません。
以上の6つのモードについて、表にまとめておきます:
| モード | 働き |
|---|---|
| "r" | 読み出し(のみの)モードでファイルをオープンする。ファイルが存在しないときはオープンできない。 |
| "w" | 書き込み(のみの)モードでファイルをオープンする。ファイルがなければ作成し、存在していれば最初にその内容を空にする。 |
| "a" | 追加モードでファイルをオープンする。ファイルがなければ作成し、存在していれば、現在の内容はそのままで、ファイル末尾に追加書き込みが行われる。 |
| "r+" | 読み書き両用のモードでファイルをオープンする。ファイルが存在しないときはオープンできない。 |
| "w+" | 読み書き両用のモードでファイルをオープンする。ファイルがなければ作成し、存在していれば最初にその内容を空にする。 |
| "a+" | 読み書き両用のモードでファイルをオープンする。ファイルがなければ作成し、存在していれば、現在の内容はそのままで、ファイル末尾に追加書き込みが行われる。 |
ファイルへデータを書き込む方法は何種類もありますが、例題では fprintf 関数を使っています。 fprintf 関数は次のような形で用いられます:
fprintf(出力ストリーム, フォーマット文字列, ...)
fprintf の第1引数は FILE 構造体へのポインタで、出力ストリームを指定します。 この出力ストリームに対して、第2引数のフォーマット文字列に従った出力が行われます。 printf 関数と fprintf 関数の違いは、printf 関数が標準出力に出力を行うのに対して、 fprintf 関数は第1引数で指定された出力ストリームに書き込みをする、 というだけのことです。すなわち、fprintf の第2引数以降の引数は、 printf の引数と同じ働きをします。
printf() 関数と同じ働きをする、ファイル出力用の fprintf() 関数が用意されていたように、1 バイトだけ標準出力に書く putchar() 関数にも同様のファイル出力用関数として fputc() 関数が用意されています。
fputc(c, outputfile); // c を出力ストリームに出力
第1引数は int 型の数値です。第2引数には出力ストリームを与えます。 fputc は第1引数 c の最下位8ビットを出力ストリームに書き込みます。 それ以外は putchar と同じです。使い方に関する注意点も同様です。
ファイルからの入力 で作成した 課題2. のプログラムを修正して、出力が標準出力ではなくファイルに出力されるようにしてください。

以下に作成にあたってのヒントと注意を列記しておきます。
ファイルからの入力 で作成した 課題3. のプログラムを修正して、出力が標準出力ではなくファイルに出力されるようにします。 データは同じものを使って下さい。
(サンプルデータ cost.txt もしくは漢字版(EUCコード) costj.txt )
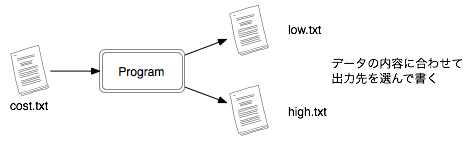
ただし、単価が150万円未満の商品と150万円以上の商品とに分けて、 別々のファイルに出力してください。
以下に作成にあたってのヒントと注意を列記しておきます。
こうしたファイル処理はコンピュータを使って行う処理の典型的なもののひとつです。 事務処理計算は当然のこと、それ以外の技術計算でもファイル入出力を伴う処理を頻繁に行います。
特に一連の課題で使っているデータは実際の全国の売り上げ台数の一日平均と、kakaku.com における最安値価格です。 ここは訓練のしどころだと思って、余裕があれば以下のようなより現実的なプログラムに取り組んでみてはどうでしょう。 気に入ったものを選んで挑戦してください。
(サンプルデータ cost.txt もしくは漢字版(EUCコード) costj.txt )
ファイルからの入力 で作成した 課題4. で組み込んだ売り上げ比較の機能を、課題 2. のプログラムに組み込んで、単価の高い車と安い車それぞれで最も総売り上げ額が高かったものを調べて出力せよ。 (出力の形式は問いません。判るようにやってくれればそれでいいです。)
サンプルデータは二つありますが、車種名が英字か漢字かの違いだけで、他の内容は同じです。 よく考えると英字と漢字の車種名が下記のように両方並んでいる方が便利そうです。
ヴィッツ Vitz T 318 1050000 カローラ COROLLA T 315 1302000 エスティマ ESTIMA T 308 2667000 フィット Fit H 233 1123500 .....(以下略)....
二つのデータファイルを読んで、このような形式のファイルを一つ作って下さい。 データを見た時に分かりやすいように桁位置も揃えておきましょう。
ファイルからの入力 で作成した 課題3. で利用したデータには、第二フィールドにメーカー記号が含まれています。 これを利用して、(課題 3. では単価によって分けていましたが)メーカーごとに仕分けて複数のファイルに出力するように修正してください。
腕に覚えのある人なら、一つ上の課題 3.3 では、こんなにたくさん似たような記述を並べるより、FILE ポインタを配列で取ってコードを集約した方が良さそうだ、ということがわかると思います。 トライしてみませんか?