
4th - "Protocol Independence" - Nick McKeown, Stanford University
Open Networking Summit 2013 April の最後のセッション、つまり大トリを務めたのは Nick McKewon だった。
Stanford で Clean Slate Program を 2006 から率い、いまの OpenFlow にまで育て上げた人だ。
この最後のセッションで Nick はスイッチハードウェア、つまりスイッチ ASIC についてこんな問いを投げかけた。
この最後のセッションで Nick はスイッチハードウェア、つまりスイッチ ASIC についてこんな問いを投げかけた。
What would an “OpenFlow-Optmized” switching chip look like?
いまの 10G Ethernet スイッチなどは中に一つか、あるいは複数のクロスバースイッチ ASIC が入っており、それらがパケットの転送を一手に引き受けている。
これらスイッチ ASIC はしかし OpenFlow 用に設計されたものではなく、OpenFlow のドライバを入れたときは、その ASIC が持っている従来的な L2/L3 転送のための仕組みを利用してフィールドマッチを掛ける。
しかし容易に想像がつくように、MAC / IP アドレスのために用意されたマッチングハードウェアでは OpenFlow の多様なマッチ処理の要求は満たせない。
すると最悪、L2 / L3 フィールド以外で(も)マッチ処理を行うようなフローエントリを設定すると、そのエントリの処理はソフトウェアによって処理されることになる。 あの貧弱な、スイッチの中にある組み込み用の PowerPC CPU などによって処理される。当たり前だけれど、遅い。
つまり「ちゃんとした」性能が出る OpenFlow スイッチを作るためには、ASIC ベンダーが OpenFlow に適したスイッチ ASIC を作らなければならない。
しかし容易に想像がつくように、MAC / IP アドレスのために用意されたマッチングハードウェアでは OpenFlow の多様なマッチ処理の要求は満たせない。
すると最悪、L2 / L3 フィールド以外で(も)マッチ処理を行うようなフローエントリを設定すると、そのエントリの処理はソフトウェアによって処理されることになる。 あの貧弱な、スイッチの中にある組み込み用の PowerPC CPU などによって処理される。当たり前だけれど、遅い。
つまり「ちゃんとした」性能が出る OpenFlow スイッチを作るためには、ASIC ベンダーが OpenFlow に適したスイッチ ASIC を作らなければならない。
ところが、作らない。
なかなか、作らない。まあまだ OpenFlow の市場的先行きが不透明で、いま作っても儲からないからだろう。
そこで Nick は "TI (Texas Instrments) と設計の練習をしてみたわ (design exsercise)" と言った。
思い切りシビれた。すごいことを言うなこの人。
そこからいきなり ASIC のアーキテクチャ説明に入った。 まず中で Action 処理を行うための VLIW な CPU コアを 100 個ほど持つようなものを作って並べるという。
そこで Nick は "TI (Texas Instrments) と設計の練習をしてみたわ (design exsercise)" と言った。
思い切りシビれた。すごいことを言うなこの人。
そこからいきなり ASIC のアーキテクチャ説明に入った。 まず中で Action 処理を行うための VLIW な CPU コアを 100 個ほど持つようなものを作って並べるという。
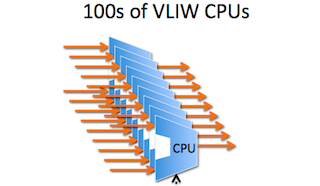
source: Nick McKeown, 2013
次にこれを 32 のパイプラインステージに並べ、TCAM もステージごとに分割して利用効率を上げながら処理をする。
これで 10G Ethernet を 64 ポート、プロセスは 28nm で 32段の Match + Action パイプラインに 1M x 40bit TCAM と370Mb の SRAM (hash table + counter 用) を入れるという。 最後はなんだか OpenFlow 向けスイッチチップ講座みたいになった。
これで 10G Ethernet を 64 ポート、プロセスは 28nm で 32段の Match + Action パイプラインに 1M x 40bit TCAM と370Mb の SRAM (hash table + counter 用) を入れるという。 最後はなんだか OpenFlow 向けスイッチチップ講座みたいになった。
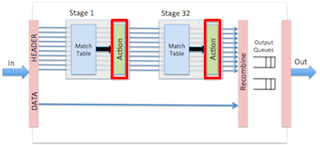
source: Nick McKeown, 2013
これは Nick からの挑戦状だ。
彼はなかなか動かない ASIC ベンダーに向かって挑戦状をたたきつけたことになる。
シリコンバレーの恐ろしいところは、大学の人間がこういうことを言ったときに、強烈なリアリティがある、ということだと思う。 スイッチ ASIC ベンダー(Broadcom など)がもしこれで動かなければ、きっと誰かが Nick に「お金出すよ?」と言うに決まっている。 Nick 自身が「こんな結果がもう出てて TI と一緒なんだけど、どう?」と持ちかけるかもしれない。
シリコンバレーの恐ろしいところは、大学の人間がこういうことを言ったときに、強烈なリアリティがある、ということだと思う。 スイッチ ASIC ベンダー(Broadcom など)がもしこれで動かなければ、きっと誰かが Nick に「お金出すよ?」と言うに決まっている。 Nick 自身が「こんな結果がもう出てて TI と一緒なんだけど、どう?」と持ちかけるかもしれない。
IBM (Fulcrum) の FM6000 は Nick のやった設計にかなり似ており、今後こうした設計のチップが増えることを期待している。
このときの Nick のプレゼンはビデオとスライド PDF が ONS のサイトに置かれている。必見。
References